ņä£ ļĪĀ
ņĀäļ¼Ėņ¦üņØś ļ│ĆĒÖöņŚÉ Ļ┤ĆĒĢ£ ņÜöņ▓ŁņØ┤ ņĀÉņ░© Ļ▒░ņäĖņ¦ĆĻ│Ā ņ׳ļŗż. ĻĘĖ ņÜöņ▓ŁņØĆ ņĄ£ĻĘ╝ ļ»ĖĻĄŁ ļīĆņäĀņØ┤ ļ│┤ņŚ¼ņŻ╝ņŚłĻ│Ā ņĀä ņäĖĻ│äņĀü Ēśäņāüņ£╝ļĪ£ ļéśĒāĆļéśĻ│Ā ņ׳ļŖö ļ░śņØ┤ņä▒ņŻ╝ņØś(anti-rationalism)ņØś ļ¼╝Ļ▓░Ļ│╝ ļŹöļČłņ¢┤ ĒĢ£ņĖĄ ņ¦äļ│┤ĒĢ£ ņĀĢļ│┤Ļ│╝ĒĢÖņØ┤ ņØ┤ņĀ£ ņĀäļ¼Ėņ¦üņØś ņ×Éļ”¼ļź╝ ļäśļ│┤ļ®░ ĻĘĖ ĒĢ┤ņ▓┤ Ļ░ĆļŖźņä▒ņØä ņĀ£ņŗ£ĒĢśļŖö ļŹ░ņŚÉņä£ ĻĖ░ņøÉĒĢśļŖö Ļ▓āņ£╝ļĪ£ ļ│┤ņØĖļŗż[1,2]. ņØśļŻīņØĖņØĆ ļ│ĆĒÖöņØś ņĢĢļĀźņØä Ļ░ĢĒĢśĻ▓ī ļ░øļŖö ņĀäļ¼Ėņ¦ü ņżæ ĒĢśļéśņØ┤ļŗż[3]. ņØĖĻ│Ąņ¦ĆļŖźņØ┤ ņØśļŻī ņĀäļ¼Ėņ¦üņØä ļīĆņ▓┤ĒĢĀ ņłś ņ׳ļŖöĻ░Ćļź╝ ļģ╝ņØśĒĢśļŖö ņé¼ņØ┤, ĒĢ£ĻĄŁņŚÉņä£ļŖö 2017ļģä ņāüļ░śĻĖ░ 6Ļ░£ņØś ļ│æņøÉņØ┤ ņÖōņŖ© Ēż ņś©ņĮ£ļĪ£ņ¦Ć(Watson for Oncology)ļź╝ ļÅäņ×ģĒ¢łļŗż. ļ│ĆĒÖöņŚÉ ļīĆņ▓śĒĢśĻĖ░ ņ£äĒĢ┤ņä£ ņÜöĻĄ¼ļÉśļŖö Ļ▓ā ņżæ ĒĢśļéśļŖö ņĄ£ĻĘ╝ņØś ņĀĢļ│┤ĻĖ░ņłĀņØś ļ│ĆĒÖöļź╝ ņØ┤ĒĢ┤ĒĢśĻ│Ā ņØ┤ļź╝ ĒÖ£ņÜ®ĒĢśļŖö Ļ▓āņØ┤ļŗż[4]. ļö░ļØ╝ņä£ ļ╣ģ ļŹ░ņØ┤Ēä░(big data)ļź╝ ļČäņäØĒĢśĻ│Ā ĒÖ£ņÜ®ĒĢĀ ņłś ņ׳ļŖö ĻĖ░Ļ│äĒĢÖņŖĄ(machine learning) ņ×ÉļŻīļČäņäØ(data analytics)ļ░®ļ▓ĢņØä ņØśĻ│╝ļīĆĒĢÖņŚÉņä£ Ļ░Ćļź┤ņ╣śĻ│Ā ņŚ░ĻĄ¼ĒśäņןņŚÉņä£ ĒÖ£ņÜ®ĒĢśļŖö ļ░®ļ▓ĢņŚÉ Ļ┤ĆĒĢ£ ļ¬©ņāēņØ┤ ĒÖ£ļ░£ĒĢśĻ▓ī ņ¦äĒ¢ēļÉśĻ│Ā ņ׳ļŗż[5,6]. ĒĢśņ¦Ćļ¦ī ĒśäņןņŚÉņä£ ņØ┤ļź╝ Ļ░Ćļź┤ņ╣śĻĖ░ ņ£äĒĢ┤ņä£ ĒĢ┤Ļ▓░ĒĢ┤ņĢ╝ ĒĢĀ ļ¼ĖņĀ£ļōżņØ┤ ņ׳ļŗż.
ļ╣ģ ļŹ░ņØ┤Ēä░ ĻĄÉņ£ĪĻ│╝ ņŚ░ĻĄ¼ļź╝ ņ£äĒĢ┤ņä£ļŖö ĒĢÖņāØļōżņŚÉĻ▓ī ĻĖ░Ļ│äĒĢÖņŖĄļ░®ļ▓ĢņØä Ļ░Ćļź┤ņ│ÉņĢ╝ ĒĢ£ļŗż. ĻĖ░Ļ│äĒĢÖņŖĄņØ┤ļ×Ć ņ×ÉļŻīņŚÉņä£ ņ╗┤Ēō©Ēä░Ļ░Ć ĒĢÖņŖĄĒĢśļŖö ļ░®ļ▓ĢņŚÉ ņ┤łņĀÉņØä ļ¦×ņČś ĒåĄĻ│äĒĢÖĻ│╝ ņ╗┤Ēō©Ēä░Ļ│╝ĒĢÖņØś ĒåĄņäŁņĀü ĒĢÖļ¼ĖņØ┤ļŗż[7]. ņØ┤Ļ▓āņØĆ ļīĆĻĘ£ļ¬© ņ×ÉļŻīņŚÉņä£ ĒåĄĻ│äņĀü ļ¬©ĒśĢņØä ĻĄ¼ņČĢĒĢśļŖö Ļ▓āņŚÉņä£ ņČ£ļ░£ĒĢśļ®░ ĒåĄĻ│äņĀü ĻĖ░ļ▓ĢĻ│╝ ļīĆĻĘ£ļ¬© ņ×ÉļŻīņØś ņĘ©ĻĖē ņ¢æņ¬ĮņØä ļŗżļŻ░ ņłś ņ׳ņ¢┤ņĢ╝ ĒĢ£ļŗż. ĒåĄĻ│äĒĢÖņØĆ ņØ┤ļ»Ė ņØśĒĢÖ ĒåĄĻ│äĒĢÖņŚÉņä£ ļŗżļŻ©Ļ│Ā ņ׳ņ£╝ļ®░, ĻĖ░Ļ│äĒĢÖņŖĄņŚÉņä£ ņé¼ņÜ®ĒĢśļŖö ĒåĄĻ│äņĀü ĻĖ░ļ▓ĢņØä ņØ┤ ņŚ░ņן ņäĀņāüņŚÉņä£ Ļ░Ćļź┤ņ╣śļŖö Ļ▓āļÅä Ļ░ĆļŖźĒĢśļŗż. ĒĢśņ¦Ćļ¦ī ļīĆĻĘ£ļ¬© ņ×ÉļŻīļź╝ ņłśņ¦æĒĢśĻ│Ā ņĀĢļ”¼ĒĢśļŖö ļ░®ļ▓ĢņØä Ļ░Ćļź┤ņ╣śĻĖ░ļŖö ņēĮņ¦Ć ņĢŖļŗż. ĻĖ░ņĪ┤ņØś ĒåĄĻ│äĒĢÖ ĻĄÉņ£ĪņŚÉņä£ņ▓śļ¤╝ Ļ░ÖņØĆ ņ×ÉļŻīļź╝ ĒĢÖņāØļōżņŚÉĻ▓ī ļéśļłĀņŻ╝Ļ│Ā ņØ┤ļź╝ ņ▓śļ”¼ĒĢśļŖö ļ░®ļ▓ĢņØĆ ņłśņŚģ ņ¦äĒ¢ēņāü ņłśņøöĒĢśņ¦Ćļ¦ī, ĒĢÖņāØļōżņØś ĒĢÖņŚģņØśņÜĢņØä Ļ│ĀņĘ©ĒĢśĻĖ░Ļ░Ć ņ¢┤ļĀĄļŗżļŖö ļé£ņĀÉņØ┤ ņĪ┤ņ×¼ĒĢ£ļŗż. ļö░ļØ╝ņä£ ĒĢÖņāØ Ļ░üĻ░üņØ┤ ņ×ÉļŻīļź╝ ņ¦üņĀæ ņłśņ¦æĒĢśĻ│Ā ņ▓śļ”¼ĒĢśļŖö ļ░®ļ▓ĢņØä Ļ░Ćļź┤ņ│ÉņĢ╝ ĒĢĀ ĒĢäņÜöņä▒ņØ┤ ņ׳ļŗż.
ņØ┤ļĢī ĒÖ£ņÜ® Ļ░ĆļŖźĒĢ£ ņ×ÉņøÉņ£╝ļĪ£ ņ▓½ņ¦Ė, Ļ│ĄĻ│ĄĻĖ░Ļ┤ĆņØ┤ ņĀ£Ļ│ĄĒĢśĻ│Ā ņ׳ļŖö Ļ│ĄĻ│Ą ļŹ░ņØ┤Ēä░Ļ░Ć ņ׳ļŗż[8]. ļæśņ¦Ė, ņŗĀļ¼ĖĻĖ░ņé¼ļéś ņØĖĒä░ļäĘ ļĖöļĪ£ĻĘĖ(internet blog), ņåīņģ£ļ»Ėļööņ¢┤(social media)ņØś ĒģŹņŖżĒŖĖ(text) ņ×ÉļŻīĻ░Ć ņ׳ļŗż. Ēøäņ×ÉļŖö ņØ┤ļ»Ė ņé¼ĒÜīĒĢÖņŚÉņä£ ņŚ¼ļ¤¼ ļ░®ņŗØņ£╝ļĪ£ ļČäņäØņØ┤ ņŗ£ļÅäļÉśĻ│Ā ņ׳ņ£╝ļ®░, ĻĄŁļé┤ņŚÉņä£ļÅä Ļ┤ĆļĀ© ļ░®ļ▓ĢļĪĀņØä ĒÖ£ņÜ®ĒĢ£ ņŚ░ĻĄ¼Ļ░Ć ĒÖ£ļ░£Ē׳ ņØ┤ļżäņ¦ĆĻ│Ā ņ׳ļŗż[9,10]. ņØ┤ļ¤░ ĒģŹņŖżĒŖĖ ņ×ÉļŻīņØś ļČäņäØņØä ĻĄÉņ£ĪņŚÉ ĒÖ£ņÜ®ĒĢśļŖö Ļ▓āņØĆ ņŚ¼ļ¤¼ ņןņĀÉņØ┤ ņ׳ļŗż. ņ▓½ņ¦Ė, ņø╣ Ēü¼ļĪżļ¦ü(web crawling), ņ”ē ņØĖĒä░ļäĘņŚÉņä£ ĒģŹņŖżĒŖĖļź╝ ņłśņ¦æĒĢśļŖö ļ░®ļ▓ĢļĪĀņØä ĻĄÉņ£ĪĒĢśņŚ¼ ĒĢÖņāØļōżņŚÉĻ▓ī ĻĖ░ļ│ĖņĀüņØĖ ņ╗┤Ēō©Ēä░ ĒöäļĪ£ĻĘĖļלļ░Ź(computer programming), ņ×ÉļŻīņłśņ¦æ ļ░Å ņĀĢļ”¼ļ░®ļ▓ĢņØä Ļ░Ćļź┤ņ╣Ā ņłś ņ׳ļŗż. ļæśņ¦Ė, ĒĢÖņāØļōżņØ┤ ņ¦üņĀæ Ļ┤Ćņŗ¼ņŻ╝ņĀ£ļź╝ ņäĀĒāØĒĢśĻ│Ā, ĒśäņŗżņØś ņ×ÉļŻīļź╝ ņ¦üņĀæ ļČäņäØĒĢĀ ņłś ņ׳ņ¢┤ ĒĢÖņāØļōżņŚÉĻ▓ī ĒĢÖņŖĄļÅÖĻĖ░ļź╝ ļČĆņŚ¼ĒĢśĻ│Ā ņØśņÜĢņØä Ļ│ĀņĘ©ĒĢĀ ņłś ņ׳ļŗż. ņģŗņ¦Ė, Ļ│╝Ļ▒░ ļČäņäØņØ┤ ņ¢┤ļĀżņøĀļŹś ļ╣äĻĄ¼ņĪ░ĒÖö ņ×ÉļŻī(unstructured data)ņØĖ ĒģŹņŖżĒŖĖ ļČäņäØļ░®ļ▓ĢņØś ĻĄÉņ£ĪņØä ĒåĄĒĢ┤ ĒĢÖņāØļōżņØ┤ ņ×ÉļŻīļČäņäØņŚÉ Ļ┤ĆĒĢ┤ Ļ░Ćņ¦ĆļŖö Ļ┤ĆņĀÉņØä ļäōĒ×É ņłś ņ׳ļŗż.
ĒģŹņŖżĒŖĖ ļČäņäØļ░®ļ▓ĢņŚÉļŖö ņŚ¼ļ¤¼ Ļ░Ćņ¦ĆĻ░Ć ņ׳ņ£╝ļ®░, ĒģŹņŖżĒŖĖļź╝ ĒåĄĒĢ┤ ņāüĒÆłņØ┤ļéś ņśüĒÖö ļō▒ņØś ĒÅēĻ░ĆņĀÉņłśļź╝ ņśłņĖĪĒĢśļŖö ļ¬©ĒśĢņØä ĻĄ¼ņČĢĒĢśļŖö Ļ░ÉņĀĢļČäņäØ(sentiment analysis), ĒģŹņŖżĒŖĖņŚÉ Ēā£ĻĘĖ(tag)ļź╝ ļČÖņŚ¼ ĒģŹņŖżĒŖĖņØś ļŗżļ®┤ņä▒ņØä ļČäņäØĒĢśĻ│Ā, ņØ┤Ļ▓āņØ┤ ļīĆņāüņØś ĒÅēĻ░ĆņÖĆļŖö ņ¢┤ļ¢╗Ļ▓ī ņŚ░Ļ▓░ļÉśļŖöņ¦Ć ĒÖĢņØĖĒĢśļŖö ņ¢æņāüļČäņäØ(aspect analysis), ļ»ĖļČäļźś ĒģŹņŖżĒŖĖļź╝ ļČäļźśĒĢśĻ│Ā, ļČäļźśļÉ£ Ļ▓░Ļ│╝ņØś ņŻ╝ņĀ£ļź╝ ĒāÉņāēĒĢśļŖö ĒåĀĒöĮ ļ¬©ļŹĖļ¦ü(topic modeling) ļō▒ņØ┤ ļīĆĒæ£ņĀüņØ┤ļŗż[11]. ļ│Ė ļģ╝ļ¼ĖņŚÉņä£ļŖö ŌĆśņäØļ®┤ŌĆÖ Ēéżņøīļō£ļĪ£ Ļ▓ĆņāēĒĢ£ ņŗĀļ¼ĖĻĖ░ņé¼ļź╝ ņłśņ¦æĒĢśņŚ¼ ņłśņ¦æĒĢ£ ĻĖ░ņé¼ļź╝ ļīĆņāüņ£╝ļĪ£ ĒĢśņŚ¼ Ļ│ĀĻĖē ĒåĀĒöĮ ļ¬©ļŹĖļ¦ü(advanced topic modeling) ļČäņäØņØä ņ¦äĒ¢ēĒĢ£ Ļ▓░Ļ│╝ļź╝ ĒģŹņŖżĒŖĖ ļČäņäØņØś ņé¼ļĪĆļĪ£ ņĀ£ņŗ£ĒĢśĻ│Āņ×É ĒĢśņśĆļŗż. ņØ┤ ņé¼ļĪĆļź╝ ĒåĄĒĢśņŚ¼ ĒģŹņŖżĒŖĖ ņłśņ¦æĻ│╝ ļČäņäØĻ│╝ņĀĢņØä ņé┤Ēö╝Ļ│Ā, ļŹöļČłņ¢┤ņä£ ņØśĻ│╝ļīĆĒĢÖņŚÉņä£ ĻĖ░Ļ│äĒĢÖņŖĄļ░®ļ▓ĢņØä ĻĄÉņ£ĪĒĢĀ ļ░®ļ▓ĢņØä Ļ│Āņ░░ĒĢśļŖö Ļ▓āņØ┤ ļģ╝ļ¼ĖņØś ļ¬®ņĀüņØ┤ļŗż.
ļ©╝ņĀĆ ĻĖ░Ļ│äĒĢÖņŖĄ ņĀüņÜ®ņØś ĻĘ╝Ļ▒░ļź╝ Ļ░£Ļ┤äĒĢśĻĖ░ ņ£äĒĢ┤ ļīĆņāüĻ│╝ ļ░®ļ▓Ģ ņäżņĀĢņØś ņØ┤ņ£Āļź╝ ņäżļ¬ģĒĢśĻ│Ā ĻĘĖ ņØ┤ļĪĀņĀü ļ░öĒāĢņØä ņé┤ĒÄ┤ļ│╝ Ļ▓āņØ┤ļŗż. ņŚ░ĻĄ¼ņ×ÉļŖö Ļ│╝Ļ▒░ ņäØļ®┤Ļ│ĄņןņØ┤ ņ׳ņŚłļŹś ņ¦ĆņŚŁņŚÉ Ļ▒░ņŻ╝ĒĢśļŹś ņŗ£ļ»╝ ņżæ ņäØļ®┤ņ£╝ļĪ£ ņØĖĒĢ£ ņ¦łļ│æņØĖ ņäØļ®┤ĒÅÉņ”ØņŚÉ Ļ▒Ėļ”░ ĒÖśņ×É ļ¬ć ļ¬ģņØä ļ®┤ļŗ┤ĒĢśņśĆļŗż. ļ®┤ļŗ┤Ļ│╝ņĀĢņŚÉņä£ ĒÖśņ×ÉļōżņØ┤ ņ×ÉņŗĀņØś ļČłĒÄĖĻ│╝ Ļ│ĀĒåĄņØ┤ ļ░öĻ╣źņŚÉ ņל ņĀäļŗ¼ļÉśņ¦Ć ņĢŖļŖöļŗżĻ│Ā ļČłļ¦īņØä ĒåĀļĪ£ĒĢśĻ│Ā ņ׳ņØīņØä ņĢīĻ▓ī ļÉśņŚłļŗż. ĻĄŁļé┤ņŚÉņä£ ņäØļ®┤ņØä ļŗżļŻ¼ ņä£ņĀüņØĆ ĒĢ£ ĻČīņØ┤ ļ░£Ļ░äļÉ£ ļ░ö ņ׳ņ£╝ļ®░, ļģ╝ļ¼ĖņØĆ ņŻ╝ļĪ£ ņżæĒö╝ņóģņØ┤ļéś ĒÅÉņ”Ø ļō▒ Ļ┤ĆļĀ© ņ¦łĒÖśĻ│╝ ņ”ØņāüņØä ļŗżļŻ¼ ņØśĒĢÖ Ļ│äņŚ┤ņØś ļģ╝ļ¼Ė, ņäØļ®┤ņØś ļ¼╝ļ”¼ņĀü, ĒÖöĒĢÖņĀü, ĒÖśĻ▓ĮņĀü ĒŖ╣ņä▒Ļ│╝ ĻĘĖ ņ▓śļ”¼ļ▓ĢņØä ļŗżļŻ¼ Ļ│ĄĒĢÖ Ļ│äņŚ┤ ļģ╝ļ¼Ė, ĻĘĖļ”¼Ļ│Ā ļČäņ¤üņØä ļŗżļŻ¼ ņé¼ĒÜī, ļ▓ĢĒĢÖ Ļ│äņŚ┤ ļģ╝ļ¼ĖņØ┤ ņŻ╝ļź╝ ņØ┤ļŻ¼ļŗż[12-15]. ĒĢÖņłĀļģ╝ļ¼ĖņØĆ ņĀäļ¼ĖņĀüņØĖ ļÅģņ×Éļź╝ ļīĆņāüņ£╝ļĪ£ ĒĢśļ»ĆļĪ£ ĒÖśņ×ÉĻ░Ć ļČłļ¦īņØä Ēæ£ĒĢ£ Ļ▓āņØĆ ņØ╝ļ░ś ļÅģņ×Éļź╝ ļīĆņāüņ£╝ļĪ£ ĒĢśļ®░ ņé¼ĒÜīņĀü ĒśäņŗżņØä ļŗżļŻ©Ļ│Ā ņ׳ļŖö ļē┤ņŖżļ¦żņ▓┤ņØ┤ļ®░, ļö░ļØ╝ņä£ ĒÖśņ×ÉļŖö ļē┤ņŖżĻĖ░ņé¼Ļ░Ć ņ×ÉņŗĀņØś Ļ▓¼ĒĢ┤ļź╝ ļīĆļ│ĆĒĢśņ¦Ć ņĢŖļŖöļŗżĻ│Ā ņØĖņŗØĒĢśĻ│Ā ņ׳ļŗżĻ│Ā Ļ░ĆņĀĢĒĢśņśĆļŗż[16].
ņØ┤ Ļ░ĆņĀĢņØä Ļ▓Ćņ”ØĒĢśĻĖ░ ņ£äĒĢ┤ņä£ ņ¦ĆĻĖłĻ╣īņ¦Ć ļ░£Ļ░äļÉ£ ļ¬©ļōĀ ņŗĀļ¼Ėņ×ÉļŻī ņżæņŚÉņä£ ņäØļ®┤ņØä ļŗżļŻ¼ ĻĖ░ņé¼ļź╝ ņ░ŠņĢä ĻĘĖ ņżæņŚÉņä£ ĒÖśņ×ÉļōżņØś ļČłĒÄĖĻ│╝ Ļ│ĀĒåĄņØä ļŗżļŻ¼ ĻĖ░ņé¼Ļ░Ć ņ׳ļŖöņ¦Ćļź╝ ĒÖĢņØĖĒĢśļŖö ļ░®ļ▓ĢņØä ņāüņĀĢĒĢĀ ņłś ņ׳ļŗż. ĻĖ░ņĪ┤ņŚÉļŖö ņäØļ®┤ņØä ļŗżļŻ¼ ĻĖ░ņé¼ļź╝ ļ¬©ļæÉ ņ░ŠļŖöļŗżļŖö Ļ▓āņØ┤ ļČłĻ░ĆļŖźĒ¢łĻ│Ā, ļŗż ņ░ŠļŖöļŗżĻ│Ā ĒĢ┤ļÅä ĻĖ░ņé¼ ņĀäņ▓┤ļź╝ ĒÖĢņØĖĒĢśņŚ¼ ņŻ╝ņĀ£ļź╝ ĒīīņĢģĒĢśļŖö Ļ▓āņØĆ ņśżļ×£ ņŗ£Ļ░äĻ│╝ ļ¦ÄņØĆ ļģĖļÅÖļĀźņØ┤ ĒĢäņÜöĒ¢łĻĖ░ņŚÉ ĒĢ┤ļŗ╣ ļ░®ļ▓ĢņØś ņĀæĻĘ╝ Ļ░ĆļŖźņä▒ņØ┤ ļé«ņĢśļŗż. ĻĘĖļ¤¼ļéś ņ╗┤Ēō©Ēä░ļź╝ ĒåĄĒĢ┤ ņØĖĒä░ļäĘņŚÉņä£ ĻĖ░ņé¼ļź╝ ņ×ÉļÅÖņ£╝ļĪ£ ņłśņ¦æĒĢśĻ│Ā, ņØ┤Ļ▓āņØä ĒģŹņŖżĒŖĖ ļČäņäØĒĢśļŖö ļ░®ļ▓ĢņØĆ ļ╣äĻĄÉņĀü Ļ░äļŗ©ĒĢśĻ▓ī ņ£äņŚÉņä£ ņĀ£ĻĖ░ļÉ£ ņ¦łļ¼ĖņØä Ļ▓Ćņ”ØĒĢĀ ņłś ņ׳ļŖö ļ░®ļ▓ĢļĪĀņØä ņĀ£ņŗ£ĒĢ£ļŗż[17,18].
ļö░ļØ╝ņä£ ņ▓śņØīņŚÉļŖö ņØĖĒä░ļäĘņŚÉņä£ Ļ┤ĆļĀ©ļÉ£ ņŗĀļ¼ĖĻĖ░ņé¼ ņĀäņ▓┤ļź╝ ņłśņ¦æĒĢśĻ│Āņ×É ĒĢśņśĆņ£╝ļéś, ņØĖĒä░ļäĘņŚÉņä£ ĻĖ░ņé¼ļź╝ Ļ▓ĆņāēĒĢĀ ņłś ņ׳ļŖö Ļ▓āņØĆ 1990ļģä ņØ┤ĒøäņØś ĻĖ░ņé¼ļ┐ÉņØ┤ļŗż. ļö░ļØ╝ņä£ Ļ▓ĆņāēļīĆņāüņØä 1990ļģä ņØ┤ĒøäņØś ĻĖ░ņé¼ļĪ£ ĒĢ£ņĀĢĒĢśņśĆļŗż. ļśÉĒĢ£ ļŗ©ņł£ĒĢśĻ▓ī ņŗĀļ¼ĖĻĖ░ņé¼ ņĀäņ▓┤ļź╝ ļ¬©ņĢä ĻĘĖ ņŻ╝ņĀ£ļź╝ ĒīīņĢģĒĢśļŖö Ļ▓āņØä ļäśņ¢┤ ņŗĀļ¼Ėņé¼ņØś ņĀĢĒīīņä▒Ļ│╝ ņŗ£ĻĖ░ņŚÉ ļö░ļØ╝ ņŗĀļ¼ĖĻĖ░ņé¼ņØś ņŻ╝ņĀ£ņŚÉ ņ░©ņØ┤Ļ░Ć ļ░£ņāØĒĢśļŖö ņ¦Ćļź╝ ĒÖĢņØĖĒĢ┤ļ│┤Ļ│Āņ×É Ē¢łļŗż. ņŗĀļ¼ĖņØ┤ ņäĖņāüņØä ļ│┤ļŖö ĒĢśļéśņØś ņ░ĮņØ┤ļØ╝ļ®┤ ĻĘĖ ņ░ĮņØĆ ņäĖņāüņØä ļ│┤ļŖö ĒŖ╣ņĀĢĒĢ£ ĒŗĆņØä ņĀ£ņŗ£ĒĢśĻ│Ā ņ׳ņ£╝ļ®░, ĻĘĖ ĒŗĆņŚÉ ļö░ļØ╝ņä£ Ļ░ÖņØĆ ņé¼ņŗżņØ┤ ļŗżļź┤Ļ▓ī ĒĢ┤ņäØļÉĀ ņłś ņ׳ļŗżļŖö Ļ▓ā, ĻĘĖļ”¼Ļ│Ā ĻĘĖ ĒŗĆņØĆ ņĀĢĒīīņä▒, ņ”ē ņĀĢņ╣śņĀü ņ×ģņןņŚÉ ļö░ļØ╝ Ēü¼Ļ▓ī Ļ▓░ņĀĢļÉ£ļŗżļŖö ĒöäļĀłņØ┤ļ░Ź ņØ┤ļĪĀ(framing theory)ņŚÉ ļö░ļź┤ļ®┤, ņäØļ®┤ņØ┤ļØ╝ļŖö ĒśäņŗżņØä ņŗĀļ¼ĖņØ┤ ņĀ£ņŗ£ĒĢśļŖö ĒŖ╣ņĀĢĒĢ£ ļ░®ņŗØņØ┤ ņĪ┤ņ×¼ĒĢĀ Ļ▓āņØ┤ļ®░, ĻĘĖĻ▓āņØĆ ņŗĀļ¼ĖņØś ņĀĢĒīīņä▒ņŚÉ ļö░ļØ╝ ņ░©ņØ┤Ļ░Ć ļéĀ Ļ▓āņØ┤ļØ╝ļŖö Ļ░ĆņäżņØä ņäĖņÜĖ ņłś ņ׳ĻĖ░ ļĢīļ¼ĖņØ┤ļŗż[19-21]. ļö░ļØ╝ņä£ ņĀĢĒīīņä▒ņØ┤ Ēü¼Ļ▓ī ļō£ļ¤¼ļéśļ®░ ņŗ£ļ»╝ļōżņØ┤ ņŻ╝ļĪ£ ĻĄ¼ļÅģĒĢśļŖö ļäż Ļ░£ņØś ņŗĀļ¼ĖņŚÉņä£ ĻĖ░ņé¼ļź╝ ņłśņ¦æĒĢśĻĖ░ļĪ£ ĒĢśņśĆļŗż[22].
ņĀĢļ”¼ĒĢśņ×Éļ®┤, ļ│Ė ļģ╝ļ¼ĖņØĆ ņäØļ®┤ Ļ┤ĆļĀ©ĒĢ£ ņŗĀļ¼ĖĻĖ░ņé¼ļź╝ ļīĆņāüņ£╝ļĪ£ ĒĢ£ ĒģŹņŖżĒŖĖ ļČäņäØļ░®ļ▓ĢņØä ĒåĄĒĢ┤ ņØśĒĢÖĻĄÉņ£ĪņŚÉņä£ ĒģŹņŖżĒŖĖ ļČäņäØ ļ░Å ĻĖ░Ļ│äĒĢÖņŖĄļ░®ļ▓ĢņØä ĻĄÉņ£ĪĒĢśĻĖ░ ņ£äĒĢ£ ņé¼ļĪĆļź╝ ņĀ£ņŗ£ĒĢśĻ│Āņ×É Ē¢łļŗż. ņé¼ļĪĆņŚÉņä£ Ļ▓Ćņ”ØĒĢśĻ│Āņ×É ĒĢśļŖö Ļ░ĆņäżņØĆ ļæÉ Ļ░Ćņ¦ĆņØ┤ļŗż. ņ▓½ņ¦Ė, ņäØļ®┤ Ēéżņøīļō£ņØś ņŗĀļ¼ĖĻĖ░ņé¼ņŚÉļŖö ĒÖśņ×ÉņØś ļČłĒÄĖĻ│╝ Ļ│ĀĒåĄ ņŻ╝ņĀ£Ļ░Ć ņל ļŗżļżäņ¦Ćņ¦Ć ņĢŖļŖöļŗż. ļæśņ¦Ė, ņŗĀļ¼ĖņØś ņĀĢĒīīņä▒ņŚÉ ļö░ļØ╝ ņäØļ®┤ Ēéżņøīļō£ņØś ņŗĀļ¼ĖĻĖ░ņé¼ ņŻ╝ņĀ£ļŖö ņ░©ņØ┤Ļ░Ć ļéĀ Ļ▓āņØ┤ļ®░, ņØ┤Ļ▓āņØĆ ņäØļ®┤ Ļ┤ĆļĀ© ĒśäņŗżņØä ļŗżļź┤Ļ▓ī ņĪ░ļ¦ØĒĢśĻ│Ā ņ׳ņØä Ļ▓āņØ┤ļŗż.
ņŚ░ĻĄ¼ļīĆņāü ļ░Å ļ░®ļ▓Ģ
1. ļŹ░ņØ┤Ēä░ ņłśņ¦æ ļ░Å ņ▓śļ”¼
1) ļŹ░ņØ┤Ēä░ ņłśņ¦æ
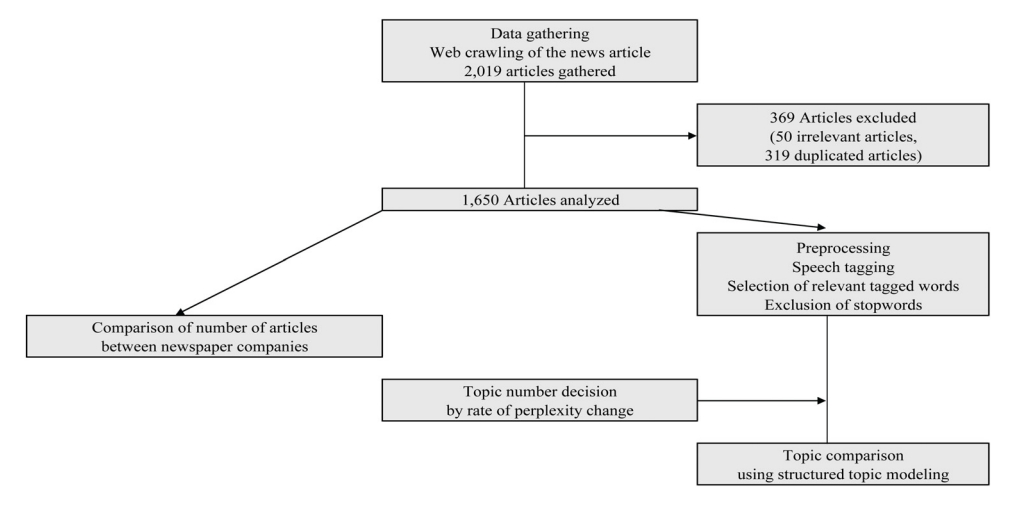
1990ļģä 1ņøö 1ņØ╝ļČĆĒä░ 2016ļģä 11ņøö 15ņØ╝Ļ╣īņ¦Ć ņĀ£ļ¬® ļ░Å ļé┤ņÜ®ņŚÉ ņäØļ®┤ņØ┤ ĒżĒĢ©ļÉ£ ņŗĀļ¼ĖĻĖ░ņé¼ļĪ£ ļ│┤ņłśņĀüņØĖ ņä▒Ē¢źņ£╝ļĪ£ ļČäļźśļÉśļŖö ņĪ░ņäĀņØ╝ļ│┤ņÖĆ ņżæņĢÖņØ╝ļ│┤, ņ¦äļ│┤ņĀüņØĖ ņä▒Ē¢źņ£╝ļĪ£ ļČäļźśļÉśļŖö ĒĢ£Ļ▓©ļĀłņÖĆ Ļ▓ĮĒ¢źņŗĀļ¼ĖņØś ĻĖ░ņé¼ļź╝ ņČöņČ£ĒĢśņŚ¼ ņŚ░ĻĄ¼ļīĆņāüņ£╝ļĪ£ ņé╝ņĢśļŗż. ņĪ░ņäĀņØ╝ļ│┤ņÖĆ ņżæņĢÖņØ╝ļ│┤ņØś Ļ▓ĮņÜ░ ņÖĖļČĆ ņé¼ņØ┤ĒŖĖņŚÉņä£ Ļ▓ĆņāēņØä ņ¦ĆņøÉĒĢśņ¦Ć ņĢŖņĢä Ļ░ü ņŗĀļ¼Ėņé¼ ĒÖłĒÄśņØ┤ņ¦ĆņŚÉņä£ ņø╣ Ēü¼ļĪżļ¦ü ĻĖ░ļ▓ĢņØä ĒåĄĒĢśņŚ¼ ņłśņ¦æĒĢśņśĆļŗż. ĒĢ£Ļ▓©ļĀłņÖĆ Ļ▓ĮĒ¢źņŗĀļ¼ĖņØś ĻĖ░ņé¼ļŖö ĒĢ£ĻĄŁņ¢ĖļĪĀņ¦äĒØźņ×¼ļŗ©ņØś ļē┤ņŖż ļ╣ģļŹ░ņØ┤Ēä░ ļČäņäØņä£ļ╣äņŖż ĒÄśņØ┤ņ¦Ć(http://www.bigkinds.or.kr)ņŚÉņä£ ļ¦łņ░¼Ļ░Ćņ¦ĆļĪ£ ņø╣ Ēü¼ļĪżļ¦ü ĻĖ░ļ▓ĢņØä ĒåĄĒĢ┤ ņłśņ¦æĒĢśņśĆļŗż. ņø╣ Ēü¼ļĪżļ¦ü ĻĖ░ļ▓ĢņØ┤ļ×Ć ņØĖĒä░ļäĘ ĒÄśņØ┤ņ¦Ć(web page)ļź╝ ņłśņ¦æĒĢśņŚ¼ ĻĘĖ ņżæņŚÉņä£ Ļ┤Ćņŗ¼ ņ׳ļŖö ļé┤ņÜ®ņØä ņČöņČ£ĒĢśļŖö Ļ▓āņØä ļ¦ÉĒĢśļ®░, ļ│Ė ļģ╝ļ¼ĖņŚÉņä£ļŖö PythonņØś Scrapy Ēī©Ēéżņ¦Ćļź╝ ĒåĄĒĢ┤ ņ×ÉļÅÖņ£╝ļĪ£ ŌĆśņäØļ®┤ŌĆÖņØä ĒżĒĢ©ĒĢśĻ│Ā ņ׳ļŖö ņŗĀļ¼ĖĻĖ░ņé¼ļź╝ ņłśņ¦æĒĢśņŚ¼ ņŗĀļ¼Ėņé¼, ņĀ£ļ¬®, ļ│┤ļÅä ņØ╝ņ×É, ļ│Ėļ¼ĖņØä ņČöņČ£ĒĢśņśĆļŗż[23,24]. ņØ┤ ļ░®ņŗØņØä ĒåĄĒĢ┤ ņłśņ¦æĒĢ£ ĻĖ░ņé¼ņØś ņ┤ØņłśļŖö 2,019Ļ░£ņśĆļŗż. ņØ┤ ņżæņŚÉņä£ Ļ▓ĆņāēļÉśņŚłņ£╝ļéś ņŗżņĀ£ļĪ£ ņäØļ®┤Ļ│╝ Ļ┤ĆļĀ©ļÉ£ ļé┤ņÜ®ņØ┤ ņĢäļŗī ĻĖ░ņé¼ 50Ļ░£, ĻĖ░Ļ░äņŚÉņä£ ļ▓Śņ¢┤ļéśĻ▒░ļéś Ļ▓Ćņāēņ¢┤ļź╝ ĒåĄĒĢ┤ņä£ļŖö ņłśņ¦æļÉśņŚłņ£╝ļéś ņŗżņĀ£ļĪ£ ļ│Ėļ¼ĖņØä ļŗ┤Ļ│Ā ņ׳ņ¦Ć ņĢŖņØĆ ĻĖ░ņé¼ 319Ļ░£ļź╝ ņĀ£ņÖĖĒĢśņśĆļŗż. Ļ▓░Ļ│╝ņĀüņ£╝ļĪ£ ļČäņäØņŚÉ ņé¼ņÜ®ĒĢ£ ņŗĀļ¼ĖĻĖ░ņé¼ņØś ņ┤ØņłśļŖö 1,650Ļ░£ņśĆļŗż.
2) ļŹ░ņØ┤Ēä░ ņĀäņ▓śļ”¼
ĒģŹņŖżĒŖĖ ļČäņäØņØĆ ļŗ©ņ¢┤ņØś ņČ£Ēśäļ╣łļÅäņŚÉ ļö░ļźĖ ĒåĄĻ│äņĀü ļ¬©ĒśĢņØä ĻĄ¼ņČĢĒĢ£ļŗż. ĒĢ£ĻĖĆņØĆ ņ¢┤ļ»ĖņŚÉ Ļ▓░ĒĢ®ĒĢśļŖö ņĪ░ņé¼Ļ░Ć ļŗżņ¢æĒĢśļ®░ ļÅÖņé¼ņØś ĒÖ£ņÜ®ĒśĢņØ┤ ļČłĻĘ£ņ╣ÖņĀüņØ┤ļŗż. ļö░ļØ╝ņä£ ĒģŹņŖżĒŖĖļź╝ ĻĘĖļīĆļĪ£ ĒÖ£ņÜ®ĒĢśņ¦Ć ņĢŖĻ│Ā, Python KoNLPy Ēī©Ēéżņ¦Ć(http://konlpy.org/ko/latest/)ņØś Twitter ĒÆłņé¼ Ēā£Ļ▒░(speech tagger)ļź╝ ĒÖ£ņÜ®ĒĢśņŚ¼ ļ¬ģņé¼ļź╝ ņČöņČ£ĒĢśņśĆļŗż[25]. ļśÉĒĢ£ ņØśļ»ĖĻ░Ć ļ¬ģĒÖĢĒĢśņ¦Ć ņĢŖņØĆ ļŗ©ņ¢┤ļŖö ļČłņÜ®ņ¢┤(stop word)ļĪ£ ņ▓śļ”¼ĒĢśņŚ¼ ļČäņäØņŚÉņä£ ņĀ£ņÖĖĒĢśņśĆļŗż. ļČłņÜ®ņ¢┤ļĪ£ ņ▓śļ”¼ĒĢ£ ļŗ©ņ¢┤ļŖö ŌĆśņäØļ®┤,ŌĆÖ ŌĆśĻĖ░ņ×ÉŌĆÖ ļō▒ ļ¬©ļōĀ ĻĖ░ņé¼ņŚÉ ļō▒ņןĒĢśļŖö ļŗ©ņ¢┤, ŌĆśļģä,ŌĆÖ ŌĆśņøö,ŌĆÖ ŌĆśņØ╝ŌĆÖ ļō▒ ņŻ╝ņĀ£ļź╝ ĒīīņĢģĒĢśļŖö ļŹ░ ļÅäņøĆņØ┤ ļÉśņ¦Ć ņĢŖļŖöļŗżĻ│Ā ĒīÉļŗ©ļÉśļŖö ļŗ©ņ¢┤, ņØśļ░ŗĻ░ÆņØ┤ ļ¬ģĒÖĢĒ׳ ļō£ļ¤¼ļéśņ¦Ć ņĢŖļŖö ŌĆśņØ┤,ŌĆÖ ŌĆśļō▒,ŌĆÖ ŌĆśĻ▓ā,ŌĆÖ ŌĆśļ░ÅŌĆÖ ļō▒ņØś ļŗ©ņ¢┤ņØ┤ļŗż.
2. ļŹ░ņØ┤Ēä░ ļČäņäØ
1) Latent dirichlet allocation ļ¬©ļŹĖņØä ĒåĄĒĢ£ ņŻ╝ņĀ£ ņČöņČ£
ļ│Ė ņŚ░ĻĄ¼ņŚÉņä£ ĒÖ£ņÜ®ĒĢ£ ĒåĀĒöĮ ļ¬©ļŹĖļ¦ü ņĢīĻ│Āļ”¼ņ”ś(topic modeling algorithm)ņØ┤ļ×Ć ņŚ¼ļ¤¼ ĒģŹņŖżĒŖĖņŚÉņä£ ļ░śļ│ĄņĀüņ£╝ļĪ£ ļéśĒāĆļéśļŖö ļŗ©ņ¢┤ņŚÉ ĻĖ░ņ┤łĒĢśņŚ¼ ņŚ¼ļ¤¼ ļ¼Ėņä£ņŚÉņä£ Ļ│ĄĒåĄņ£╝ļĪ£ ļéśĒāĆļéśļŖö ņ×Āņ×¼ņĀüņØĖ Ēī©Ēä┤(latent pattern)ņØä ņČöņĀĢĒĢśļŖö Ļ▓āņØä Ļ░Ćļ”¼Ēé©ļŗż[26]. ļ╣äņŖĘĒĢ£ ņŻ╝ņĀ£ļź╝ Ļ░Ćņ¦ĆĻ│Ā ņ׳ļŖö ĒģŹņŖżĒŖĖļŖö ļ╣äņŖĘĒĢ£ ļŗ©ņ¢┤ļź╝ ĒÖ£ņÜ®ĒĢśņŚ¼ ĻĖ░ņłĀĒĢśĻ│Ā ņ׳ņØä Ļ▓āņ£╝ļĪ£ ņāØĻ░üĒĢĀ ņłś ņ׳ļŗż. ņśłņ╗©ļīĆ ĒÅÉļĀ┤, ņ¦łļ│æ, ĒĢŁņāØņĀ£, ņÖĖĻ│╝ņĀü ņłĀņŗØ ļō▒ņØś Ēæ£ĒśäņØ┤ ņ×ÉņŻ╝ ļéśĒāĆļéśļŖö ĒģŹņŖżĒŖĖļŖö ņØśļŻī ĒģŹņŖżĒŖĖļĪ£, ņČĢĻĄ¼, Ļ│©ĒéżĒŹ╝, Ļ┤Ćņżæ, ņŗ¼ĒīÉ ļō▒ņØś Ēæ£ĒśäņØ┤ ņ×ÉņŻ╝ ļéśĒāĆļéśļŖö ĒģŹņŖżĒŖĖļŖö ņŖżĒżņĖĀ ĒģŹņŖżĒŖĖļØ╝Ļ│Ā ļ│╝ ņłś ņ׳ļŗż. ĻĘĖļ”¼Ļ│Ā ņśłņ╗©ļīĆ, ņŗ¼ņןļé┤Ļ│╝ ļģ╝ļ¼ĖņŚÉļŖö myocardial infarction (MI)ņØ┤ ļ¦ÄņØ┤ ļō▒ņןĒĢśņ¦Ćļ¦ī, ņŗĀĻ▓ĮņÖĖĻ│╝ ļģ╝ļ¼ĖņŚÉļŖö ņל ļō▒ņןĒĢśņ¦Ć ņĢŖņØä Ļ▓āņØ┤ļØ╝Ļ│Ā ņśłņāüĒĢĀ ņłś ņ׳ņ£╝ļ®░, MIĻ░Ć ļ¦ÄņØ┤ ļō▒ņןĒĢśļŖö ļģ╝ļ¼ĖņØś ņŻ╝ņĀ£Ļ░Ć MIņÖĆ ņŚ░Ļ▓░ļÉśņ¢┤ ņ׳ņØä Ļ▓āņØ┤ļØ╝Ļ│Ā Ļ░ĆņĀĢĒĢśļŖö Ļ▓āņØĆ ĒāĆļŗ╣ĒĢĀ ņłś ņ׳ļŗż. ņØ┤ļĀćĻ▓ī ĒģŹņŖżĒŖĖņØś ņ¦æĒĢ®ņŚÉņä£ ņ×ÉņŻ╝ ņČ£ĒśäĒĢśļŖö ļŗ©ņ¢┤ļź╝ ĻĘĖ ņ¦æĒĢ®ņØś ĒŖ╣ņä▒ņØä ļ░śņśüĒĢśĻ│Ā ņ׳ļŖö ņżæņŗ¼ļŗ©ņ¢┤ļØ╝Ļ│Ā ļ│Ėļŗżļ®┤, ĻĘĖļ¤░ ļŗ©ņ¢┤ļź╝ ļ¬©ņĢä ĒģŹņŖżĒŖĖ ņ¦æĒĢ®ņØś ņŻ╝ņĀ£ļź╝ ĻĄ¼ņä▒ĒĢśļŖö Ļ▓āņØ┤ Ļ░ĆļŖźĒĢśļ”¼ļØ╝ļŖö Ļ░ĆņĀĢņŚÉņä£ ņČ£ļ░£ĒĢ£ Ļ▓āņØ┤ ĒåĀĒöĮ ļ¬©ļŹĖļ¦üņØ┤ļŗż.
ĻĘĖ ņżæ ņĄ£ĻĘ╝ Ļ░Ćņן ļ¦ÄņØ┤ ĒÖ£ņÜ®ļÉśĻ│Ā ņ׳ļŖö latent dirichlet allocation (LDA)ņØĆ Ļ░ü ļ¼Ėņä£ļŖö ņŚ¼ļ¤¼ Ļ░£ņØś ĒåĀĒöĮņØä Ļ░Ćņ¦ĆĻ│Ā ņ׳ļŗżĻ│Ā Ļ░ĆņĀĢĒĢśļŖö Ļ▓āņŚÉņä£ ņČ£ļ░£ĒĢ£ļŗż. ņØ┤ļĢī Ļ░ü ĒåĀĒöĮņØĆ ņŚ¼ļ¤¼ ļ¼Ėņä£ņŚÉņä£ ļ░śļ│ĄņĀüņ£╝ļĪ£ ļéśĒāĆļéśļŖö ļŗ©ņ¢┤ņØś ņ¦æĒĢ®ņØ┤ļ»ĆļĪ£ ņØ╝Ļ┤Ćņä▒ņØä ņ¦Ćļŗīļŗż. ļŗ©, ļŗ©ņ¢┤ņØś ļ¼ČņØīņØĖ ĒåĀĒöĮņØ┤ Ļ░Ćņ¦ĆļŖö ņØ╝Ļ┤Ćņä▒Ļ│╝ļŖö ļ│äĻ░£ļĪ£ ņäĀņĀĢļÉ£ ļŗ©ņ¢┤ļź╝ ņ¢┤ļ¢╗Ļ▓ī ĒĢ┤ņäØĒĢĀ Ļ▓āņØĖņ¦ĆļŖö ņĄ£ņóģņĀüņ£╝ļĪ£ ņŚ░ĻĄ¼ņ×ÉņŚÉĻ▓ī ļŗ¼ļĀż ņ׳ļŗż[27]. ļ│Ė ņŚ░ĻĄ¼ņŚÉņä£ļŖö ņØśļŻīņØĖļ¼ĖĒĢÖĻ│╝ ņé░ņŚģņØśĒĢÖņØä ņĀäĻ│ĄĒĢ£ ņäĖ ņŚ░ĻĄ¼ņ×ÉĻ░Ć ņĄ£ņóģņĀüņ£╝ļĪ£ ņäĀņĀĢļÉ£ ĒåĀĒöĮ ļŗ©ņ¢┤ņ¦æĒĢ®ņØä ĒĢ┤ņäØĒĢśĻ│Ā ņØ┤ļź╝ ļ╣äĻĄÉĒĢśņŚ¼ ņĄ£ņóģņĀüņ£╝ļĪ£ ĒåĀĒöĮņØś ņĀ£ļ¬®ņØä Ļ▓░ņĀĢĒĢśņśĆļŗż.
LDAļŖö ĒģŹņŖżĒŖĖņŚÉņä£ ļéśĒāĆļéśļŖö ĒåĀĒöĮņØś ņłśĻ░Ć ņäĀĒŚśņĀüņ£╝ļĪ£ ņŻ╝ņ¢┤ņ¦ä Ļ▓āņ£╝ļĪ£ Ļ░ĆņĀĢĒĢ£ļŗż. ņ”ē, ņśłļź╝ ļōżļ®┤ Ēśäņ×¼ ĒģŹņŖżĒŖĖņØś ņŻ╝ņĀ£Ļ░Ć 10Ļ░£ļØ╝Ļ│Ā ņŻ╝ņ¢┤ņ¦Ćļ®┤, ņĢīĻ│Āļ”¼ņ”śņØĆ ņŚ┤ Ļ░£ņØś ņŻ╝ņĀ£ļź╝ ĒāÉņāēĒĢśņŚ¼ Ļ▓░Ļ│╝ļź╝ ņĀ£ņČ£ĒĢ£ļŗż. ĻĖ░Ļ│äĒĢÖņŖĄ ņØ╝ļ░śņŚÉņä£ļŖö ļ¬©ĒśĢņØś ņĪ░Ļ▒┤(parameter)ņØä Ļ▓░ņĀĢĒĢĀ ļĢī, ņśłņĖĪļ¬©ĒśĢņØä ĒåĄĒĢ£ ņśłņĖĪĻ░ÆĻ│╝ ņŗżņĀ£Ļ░ÆņØś ņ░©ņØ┤ļź╝ ļéśĒāĆļé┤ļŖö ņåÉņŗżĒĢ©ņłś(loss function)ļĪ£ ĒÅēĻĘĀņĀ£Ļ│▒ņśżņ░©(mean squared error) ļō▒ņØś Ļ░ÆņØä ĒÖ£ņÜ®ĒĢśņŚ¼ ņĄ£ņĀü ņĪ░Ļ▒┤ņØä Ļ▓░ņĀĢĒĢ£ļŗż. ĒĢśņ¦Ćļ¦ī ĒģŹņŖżĒŖĖ ņ×ÉļŻīņŚÉņä£ļŖö ĒÅēĻĘĀņĀ£Ļ│▒ņśżņ░©ļź╝ ņé¼ņÜ®ĒĢĀ ņłś ņŚåņ¢┤ ļ¼Ėņן ĻĖĖņØ┤ņŚÉ ļö░ļźĖ ļ│Ąņ×Īņä▒ ļ╣äĻĄÉļź╝ ņ£äĒĢ┤ Ļ│äņé░ļÉ£ ņŚöĒŖĖļĪ£Ēö╝ Ļ░ÆņØä ļŗ©ņ¢┤ Ļ░£ņłśļĪ£ ļéśļłł ļŗ©ņ¢┤ļŗ╣ ļ╣äĒŖĖ(bit per words)ļź╝ ĒåĄĒĢ┤ ĻĄ¼ĒĢ£ Ēś╝ļ×ĆļÅä(perplexity)ļź╝ ĒÖ£ņÜ®ĒĢ£ļŗż. ņĄ£ĻĘ╝ ņØ┤ Ļ░ÆņØä ĒåĄĒĢ┤ ņĀüņĀłĒĢ£ ĒåĀĒöĮ ņłśļź╝ Ļ▓░ņĀĢĒĢĀ ņłś ņ׳ļŗżļŖö ņŚ░ĻĄ¼Ļ░Ć ņĀ£ņŗ£ļÉśĻ│Ā ņ׳ņ£╝ļ®░, ļ│Ė ņŚ░ĻĄ¼ņŚÉņä£ļÅä Zhao ļō▒[28]ņØś ņŚ░ĻĄ¼ļź╝ ļö░ļØ╝ Ēś╝ļ×ĆļÅä ļ│ĆĒÖöņ£©(rate of perplexity change)ņØä ņ¦ĆĒæ£ļĪ£ ņé¼ņÜ®ĒĢśņśĆļŗż.
Ēś╝ļ×ĆļÅäļŖö ņĀĢļ│┤ņØ┤ļĪĀ(information theory)ņŚÉņä£ ĒåĄĻ│äņĀü ļ¬©ĒśĢņØ┤ ņ×ÉļŻīļź╝ ņל ņäżļ¬ģĒĢśļŖöņ¦ĆņØś ņĀĢļÅäļź╝ ĒÅēĻ░ĆĒĢśļŖö ļŹ░ņŚÉ ĒØöĒ׳ ņé¼ņÜ®ļÉśļŖö ņłśņ╣śļĪ£ ļé«ņØäņłśļĪØ ļŹö ņóŗļŗż(Figure 1). ņØ┤ Ļ░ÆņŚÉ ĻĖ░ļ░śņØä ļæÉņ¢┤ ĒåĀĒöĮņØś Ļ░£ņłś Ļ▓░ņĀĢņØä ņ£äĒĢ┤ņä£ļŖö Ēś╝ļ×ĆļÅä ļ│ĆĒÖöņ£©ņØä ĻĄ¼Ļ░äļ¦łļŗż Ļ│äņé░ĒĢśņŚ¼ Ēś╝ļ×ĆļÅä ļ│ĆĒÖöņ£©ņØ┤ ņĄ£ņ┤łļĪ£ ņĄ£ņåīĒÖöļÉśļŖö Ļ░ÆņØä ĒåĀĒöĮņØś ņłśļĪ£ ņé╝ņĢśļŗż. ĻĘĖ Ļ▓░Ļ│╝ ņØ╝Ļ░äņ¦Ć ĻĖ░ņé¼ņŚÉ ņ׳ņ¢┤ ĒåĀĒöĮ Ļ░£ņłśņŚÉ ļö░ļźĖ Ēś╝ļ×ĆļÅä ļ│ĆĒÖöņ£©ņØä ĻĄ¼ĒĢśņŚ¼ ĒåĀĒöĮ ņłśļź╝ 6Ļ░£ļĪ£ Ļ▓░ņĀĢĒĢśĻ│Ā ļ¬©ĒśĢņØä ĻĄ¼ņČĢĒĢśņśĆļŗż(Figure 2). ņØ┤ļĢī ļ│ĆĒÖöņ£© Ļ│ĪņäĀņØś ņ¦äĒ¢ē ļ░®Ē¢źņŚÉ ļ¬ģĒÖĢĒĢ£ ņ░©ņØ┤Ļ░Ć ļéśĒāĆļéśļŖö ņ¦ĆņĀÉ, ņ”ē ņĄ£ņåī ļ│ĆĒÖöņ£©ņØä ļéśĒāĆļé┤ļŖö ĻĄ¼Ļ░äņØä ņäĀĒāØĒĢśņśĆļŗż.
2) ĻĄ¼ņĪ░ĒÖö ĒåĀĒöĮ ļ¬©ļŹĖļ¦üņØä ĒåĄĒĢ£ ņĀĢĒīīņä▒ ļ░Å ņŗ£Ļ│äņŚ┤ņŚÉ ļö░ļźĖ ĒåĀĒöĮļČäņäØ
LDA ņ×Éņ▓┤ļŖö ļ¼Ėņä£ņØś ĻĄ░ņ¦æņØä ņ£äĒĢśņŚ¼ Ļ░£ļ░£ļÉśņŚłņ£╝ļ®░, ņĀÉņ░© ļīĆĻĘ£ļ¬© ļ¼Ėņä£ļź╝ ļČäņäØĒĢśĻĖ░ ņ£äĒĢ£ ņ£ĀņÜ®ĒĢ£ ļÅäĻĄ¼ļĪ£ ņ×Éļ”¼ ņ×ĪĻ│Ā ņ׳ļŗż[29]. ĻĘĖļ¤¼ļéś ĒåĀĒöĮ ļ¬©ļŹĖļ¦üņØĆ ļŗ©ņł£Ē׳ ņĀäņ▓┤ ļ¼Ėņä£ņØś ĒåĀĒöĮņØä ļéśņŚ┤ĒĢĀ ļ┐ÉņØ┤ļ»ĆļĪ£ Ļ▓░Ļ│╝ņŚÉņä£ ļÅäņČ£ĒĢĀ ņłś ņ׳ļŖö ļé┤ņÜ®ņØĆ ļ¦Äņ¦Ć ņĢŖļŗż. ļö░ļØ╝ņä£ ĒåĀĒöĮ ļ¬©ļŹĖļ¦üņŚÉ Ļ│Ąļ│Ćļ¤ē(covariate)ņØä Ļ▓░ĒĢ®ĒĢśņŚ¼ ļČäņäØĒĢśĻ│Āņ×É ĒĢśļŖö ņŗ£ļÅäĻ░Ć ņ׳ņŚłļŗż[30-32]. ĻĄŁļé┤ņŚÉņä£ļÅä ņØ┤ļź╝ ĒåĄĒĢ┤ ņŗĀļ¼Ėņ×ÉļŻīņØś ņśżĒö╝ļŗłņ¢Ė ļ¦łņØ┤ļŗØņØä ņŗ£ļÅäĒĢ£ ņŚ░ĻĄ¼Ļ░Ć ņ׳ņŚłļŗż[9]. ĒĢśņ¦Ćļ¦ī ņäĀĒ¢ēņŚ░ĻĄ¼ļŖö ĒåĀĒöĮļ╣äņ£©ņŚÉ ļīĆĒĢ£ ņŗ£Ļ│äņŚ┤ņĀü ļČäņäØņØ╝ ļ┐É ĒåĀĒöĮĻĄ¼ņä▒Ļ│╝ ļ│ĆĒÖöņŚÉ Ļ│Ąļ│Ćļ¤ēņØ┤ ņ¢┤ļ¢╗Ļ▓ī ņśüĒ¢źņØä ļ»Ėņ╣śļŖöņ¦ĆļŖö ļ│┤ņŚ¼ņŻ╝ņ¦Ć ļ¬╗ĒĢ£ļŗżļŖö ĒĢ£Ļ│äĻ░Ć ņ׳ņŚłļŗż. ņĄ£ĻĘ╝ ļ░£Ēæ£ļÉ£ ĻĄ¼ņĪ░ĒÖö ĒåĀĒöĮ ļ¬©ļŹĖļ¦ü(structured topic modeling, STM)ņØĆ ņŚ¼ĻĖ░ņŚÉņä£ ĒĢ£ ļ░£ņ¦Ø ļŹö ļéśņĢäĻ░Ć Ļ│Ąļ│Ćļ¤ēņØä ņ¦üņĀæ ļ¬©ļŹĖļ¦üņŚÉ Ļ▓░ĒĢ®ĒĢśņŚ¼ ĒģŹņŖżĒŖĖņØś Ļ│Ąļ│Ćļ¤ēņØ┤ ĒåĀĒöĮļ╣äņ£©Ļ│╝ ļé┤ņÜ®ņŚÉ ņśüĒ¢źņØä ļ»Ėņ╣śļŖö ņĀĢļÅäļź╝ ļČäņäØĒĢśļŖö ļ░®ļ▓ĢļĪĀņØ┤ļŗż[33]. ņŚ¼ĻĖ░ņŚÉņä£ Ļ│Ąļ│Ćļ¤ēņØ┤ļ×Ć ļ│Ė ņŚ░ĻĄ¼ņŚÉņä£ņØś ņŗĀļ¼Ėņé¼ļéś ļ│┤ļÅäņØ╝ņ×ÉņÖĆ Ļ░ÖņØ┤ ĒģŹņŖżĒŖĖ ņ×ÉļŻī Ļ░ü ĒĢŁņØś ļ¦żĻ░£, ņłśņ╣ś ļ│Ćņłśļź╝ Ļ░Ćļ”¼Ēé©ļŗż. ņśłņ╗©ļīĆ ņŗĀļ¼Ėņé¼ņŚÉ ļö░ļźĖ ĒåĀĒöĮļ╣äņ£©ņØś ņ░©ņØ┤ļź╝ ĒÖĢņØĖĒĢśņŚ¼ ņŗĀļ¼Ėņé¼Ļ░Ć ĒĢ┤ļŗ╣ ņé¼Ļ▒┤ņØä ļ░öļØ╝ļ│┤ļŖö Ļ┤ĆņĀÉņØś ņ░©ņØ┤ļź╝ ĒÖĢņØĖĒĢĀ ņłś ņ׳ļŗż.
ņĢ×ņä£ Ēś╝ļ×ĆļÅä ļ│ĆĒÖöņ£©ņØä ĒåĄĒĢ┤ Ļ▓░ņĀĢĒĢ£ ĒåĀĒöĮ ņłś 6Ļ░£ļź╝ ņé¼ņÜ®ĒĢśņŚ¼ ļ¦żņ▓┤ņÖĆ ļ│┤ļÅäņØ╝ņ×Éļź╝ Ļ│Ąļ│Ćļ¤ēņ£╝ļĪ£ ĒÖ£ņÜ®ĒĢśņŚ¼ ņĀäņ▓┤ ĻĖ░ņé¼ļź╝ ļīĆņāüņ£╝ļĪ£ R ĒÖśĻ▓ĮņŚÉņä£ STM Ēī©Ēéżņ¦Ć(http://cran.r-project.org/web/packages/stm/index.html)ļź╝ ĒåĄĒĢ┤ ļČäņäØņØä ņŗżņŗ£ĒĢśņśĆļŗż[34]. ĒÖśņ×ÉņØś ļČłĒÄĖĻ│╝ Ļ┤ĆļĀ©ĒĢ£ ĒåĀĒöĮņØ┤ ļéśĒāĆļéśļŖöņ¦Ć, ĻĘĖļ”¼Ļ│Ā Ļ░ü ļ¦żņ▓┤ņØś ĒåĀĒöĮĻĄ¼ņä▒ņØś ņ░©ņØ┤ļź╝ ĒåĄĒĢ┤ ĒöäļĀłņØ┤ļ░ŹņØś ņ░©ņØ┤ļź╝ ĒÖĢņØĖĒĢĀ ņłś ņ׳ļŖöņ¦ĆņØś Ļ░ĆņäżņØä ĒÖĢņØĖĒĢśĻĖ░ ņ£äĒĢ┤ ņäĖ ļŗ©Ļ│äļĪ£ ļČäņäØĒĢśņśĆļŗż. ņÜ░ņäĀ, ļ¦żņ▓┤ļ│ä ĻĖ░ņé¼ņØś ļ╣łļÅäņłś ņ░©ņØ┤ļź╝ ĒÖĢņØĖĒĢśņśĆļŗż. ļŗżņØī, ļ¦żņ▓┤ņÖĆ ņŗ£Ļ│äņŚ┤ņŚÉ ļö░ļØ╝ ĒåĀĒöĮņØś ļ│ĆĒÖöļź╝ Ļ┤Ćņ░░ĒĢśņśĆļŗż. ļ¦żņ▓┤ņØś ĒöäļĀłņØ┤ļ░ŹņŚÉ ļö░ļØ╝ ĒåĀĒöĮņØś ĻĄ¼ņä▒ņØĆ ņ¢┤ļ¢╗Ļ▓ī ļ│ĆĒĢśļŖöņ¦Ć, ĻĘĖļ”¼Ļ│Ā ņŗ£Ļ░äņŚÉ ļö░ļØ╝ ņ¢┤ļ¢ż ņ░©ņØ┤ļź╝ ļ│┤ņØ┤ļŖöņ¦Ć ĒÖĢņØĖĒĢśņśĆļŗż. ņØ┤ņ¢┤ņä£ ņØ┤ļź╝ ĒåĄĒĢ┤ ņ¦äļ│┤ļ¦żņ▓┤ņÖĆ ļ│┤ņłśļ¦żņ▓┤ņŚÉ ļ░£Ēæ£ļÉ£ ņäØļ®┤ Ļ┤ĆļĀ© ĻĖ░ņé¼ņØś ĒåĀĒöĮĻĄ¼ņä▒ņØä ļ╣äĻĄÉĒĢśņśĆļŗż. ļģ╝ļ¼ĖņŚÉņä£ņØś ļČäņäØĻ│╝ņĀĢņØä ņÜöņĢĮĒĢśņŚ¼ Figure 3ņŚÉ ņĀ£ņŗ£ĒĢśņśĆļŗż.
Ļ▓░ Ļ│╝
1. ņĀ£ļ¬® ļ░Å ļé┤ņÜ®ņŚÉ ņäØļ®┤ņØ┤ ĒżĒĢ©ļÉśņ¢┤ ņ׳ļŖö ĻĖ░ņé¼ņØś ņŗĀļ¼Ėņé¼ļ│ä ļČäĒż
ņ¦äļ│┤ņĀüņØĖ ļ¦żņ▓┤ļĪ£ ļČäļźśļÉ£ ņŻ╝ņÜö ņ¢ĖļĪĀņØĆ ļ│┤ņłśņĀüņØĖ ļ¦żņ▓┤ņŚÉ ļ╣äĒĢ┤ ļŹö ļ╣łļ▓łĒĢśĻ▓ī ņäØļ®┤ņØä ļŗżļŻ©Ļ│Ā ņ׳ņŚłļŗż(Table 1). ļśÉĒĢ£ ņĀĢĒīīņä▒ņŚÉ ļö░ļØ╝ ĻĖ░ņé¼ ņłśņŚÉ Ēü░ ņ░©ņØ┤Ļ░Ć ņ׳ņŚłļŗż. ņĪ░ņäĀņØ╝ļ│┤ļŖö Ļ┤ĆļĀ© ĻĖ░ņé¼ 183Ļ▒┤ņ£╝ļĪ£ ņäØļ®┤ ļ¼ĖņĀ£ļź╝ Ļ░Ćņן ņĀüĻ▓ī ļŗżļŻ©Ļ│Ā ņ׳ņŚłņ¦Ćļ¦ī ĒĢ£Ļ▓©ļĀłļŖö Ļ┤ĆļĀ© ĻĖ░ņé¼ 663Ļ▒┤ņ£╝ļĪ£ ņäØļ®┤ ļ¼ĖņĀ£ļź╝ Ļ░Ćņן ļ¦ÄņØ┤ ļŗżļŻ©Ļ│Ā ņ׳ņŚłļŗż.
2. ņ×ÉļÅÖĒÖöļÉ£ ĒģŹņŖżĒŖĖ ļČäņäØņØä ņ£äĒĢ£ ĻĖ░ņé¼ņØś ĒåĀĒöĮ ņłś ņäĀņĀĢ
6Ļ░£ņØś ĒåĀĒöĮņŚÉ ļīĆĒĢ┤ ĒåĀĒöĮ ļĖīļØ╝ņÜ░ņĀĆ(topic browser)ļź╝ ĒåĄĒĢ┤ Ļ░üĻ░üņØä ņĪ░ņé¼, Ļ░£ļ│ä ĒåĀĒöĮņØä Ļ▓░ņĀĢĒĢśĻ│Ā ĒåĀĒöĮņŚÉ ņĀ£ļ¬®ņØä ļČĆņŚ¼ĒĢśņśĆļŗż[26]. ĒåĀĒöĮ ļĖīļØ╝ņÜ░ņĀĆļ×Ć ĒĢ┤ļŗ╣ ĒåĀĒöĮņØś ņżæņŗ¼ļŗ©ņ¢┤ņÖĆ Ļ░Ćņן Ļ┤ĆļĀ©ņä▒ņØ┤ ļåÆņØĆ ĒģŹņŖżĒŖĖļź╝ ņĀ£ņŗ£ĒĢśņŚ¼ ĒåĀĒöĮņØś ņĀ£ļ¬® ņäżņĀĢņØä ņÜ®ņØ┤ĒĢśĻ▓ī ĒĢśļŖö ņĀ£ņŗ£ļ▓ĢņØä Ļ░Ćļ”¼Ēé©ļŗż. ņØ┤ļź╝ ĒåĄĒĢ┤ ĒÖĢņØĖĒĢ£ ņĀäņ▓┤ ĻĖ░ņé¼ņØś ĒåĀĒöĮņØĆ ļŗżņØīĻ│╝ Ļ░Öļŗż(Appendix 1).
Ļ░ü ĒåĀĒöĮņØś ņĀäņ▓┤ ļ¼Ėņä£ņŚÉņä£ņØś ļ╣äņ£©ņØä Ēæ£ņŗ£ĒĢśņśĆļŗż. ļŗżņØī, ņśłņŗ£ļĪ£ ĒåĀĒöĮ 1, 2ņÖĆ ņĄ£ļīĆ ņŚ░Ļ┤Ćņä▒ņØä ļ│┤ņØ┤ļŖö ļ¼Ėņä£ļź╝ ļÅäĒæ£ļĪ£ Ēæ£ņŗ£ĒĢśņśĆļŗż(Appendix 2). Ļ▒┤ļ¼╝, Ēśäņן ņäØļ®┤ Ļ▓ĆņČ£ ĒåĀĒöĮņØś ļ╣äņ£©ņØ┤ ņāüļīĆņĀüņ£╝ļĪ£ ļåÆĻ│Ā, ļéśļ©Ėņ¦Ć ĒåĀĒöĮņØś ļ╣äņ£©ņØĆ ņ£Āņé¼ĒĢśņśĆļŗż. ņé¼Ļ│Ā ĒåĀĒöĮņØś Ļ▓ĮņÜ░ 1994ļģä ļ░£ņāØĒĢ£ ņé╝ĒÆŹļ░▒ĒÖöņĀÉ ņé¼Ļ│Ā ļō▒ņŚÉņä£ ņé¼Ļ│ĀĒÖśĻ▓ĮņØä ļ¼śņé¼ĒĢĀ ļĢī ŌĆśņäØļ®┤ŌĆÖĻ│╝ ŌĆśņäØļ®┤ Ļ░ĆļŻ©ŌĆÖĻ░Ć ņ¢ĖĻĖēļÉśņ¢┤ ņØ┤ļź╝ ļŗżļŻ¼ ļŗżņłśņØś ĻĖ░ņé¼Ļ░Ć ĒżĒĢ©ļÉśņ¢┤ ņ׳ņŚłļŗż.
3. ĻĄ¼ņĪ░ĒÖö ĒåĀĒöĮ ļ¬©ļŹĖļ¦ü ļČäņäØņØä ĒåĄĒĢ£ ņ¢ĖļĪĀņé¼ļ│ä, ĻĖ░Ļ░äļ│ä ĻĖ░ņé¼ ļ╣äĻĄÉ
ļŗżņØī, STMĻĖ░ļ▓ĢņØä ĒåĄĒĢ┤ ņ¢ĖļĪĀņé¼ņØś ņĀĢĒīīņä▒ ļ░Å ņŗ£ĻĖ░Ļ░Ć ĒåĀĒöĮņØś ļ╣äņ£©ņŚÉ ļ»Ėņ╣śļŖö ņśüĒ¢źņØä ļČäņäØĒĢśņśĆļŗż.
1) ņĀĢĒīīņä▒ņØ┤ ĒåĀĒöĮ ļ╣äņ£©ņŚÉ ļ»Ėņ╣śļŖö ņśüĒ¢ź
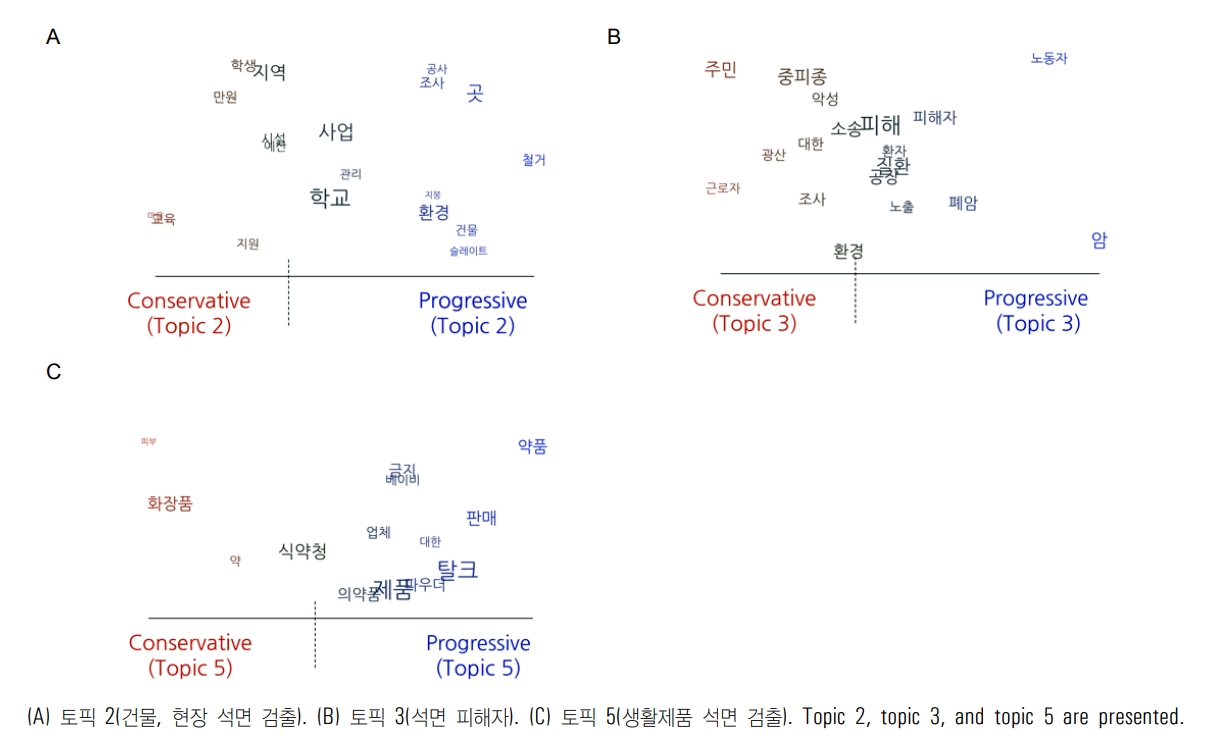
ņĀĢĒīīņä▒ņØ┤ ĒåĀĒöĮ ļ╣äņ£©ņŚÉ ļ»Ėņ╣śļŖö ņśüĒ¢źņØä ļ│┤ļ®┤, ņ¦äļ│┤ļ¦żņ▓┤ļŖö ĒåĀĒöĮ 1(ĒÖśĻ▓Į ļ¼ĖņĀ£), ĒåĀĒöĮ 2(Ļ▒┤ļ¼╝, ĒÖśĻ▓Į ņäØļ®┤ Ļ▓ĆņČ£), ĒåĀĒöĮ 3(ņäØļ®┤ Ēö╝ĒĢ┤ņ×É)ņØä ļŹö ļ¦ÄņØ┤ ļŗżļŻ©Ļ│Ā ņ׳ņŚłļŗż. ļ░śļ®┤ ļ│┤ņłśļ¦żņ▓┤ļŖö ĒåĀĒöĮ 4(ļ░£ņĢöļ¼╝ņ¦ł), ĒåĀĒöĮ 5(ņāØĒÖ£ņĀ£ĒÆł ņäØļ®┤ Ļ▓ĆņČ£), ĒåĀĒöĮ 6(ņé¼Ļ│Ā)ņØä ļŹö ļ¦ÄņØ┤ ļŗżļŻ©Ļ│Ā ņ׳ņŚłļŗż. ĒåĀĒöĮ 1ņØĆ ņĀäļ░śņĀüņØĖ ĒÖśĻ▓Į ļ¼ĖņĀ£ļź╝ ļŗżļŻ©Ļ│Ā ņ׳ņ£╝ļ®░, ĒåĀĒöĮ 4ļŖö ņäØļ®┤ņØä ĒżĒĢ©ĒĢ£ ļ░£ņĢöļ¼╝ņ¦ł ļ¬©ļæÉļź╝ ņŻ╝ņĀ£ļĪ£ Ē¢łļŗż. ĒåĀĒöĮ 6ņØĆ ņé¼Ļ│Āļź╝ ņŻ╝ņĀ£ļĪ£ ņé╝Ļ│Ā ņ׳ņŚłļŖöļŹ░, ņØ┤Ļ▓āņØĆ ņé¼Ļ│ĀĒśäņן ļō▒ņŚÉņä£ ņäØļ®┤ņØ┤ ņ£ĀņČ£ļÉśļŖö ļĢīļÅä ņ׳ĻĖ░ ļĢīļ¼ĖņØ┤ļŗż. ņØ┤ ĒåĀĒöĮļōżņØĆ ņ¦üņĀæ ņäØļ®┤Ļ│╝ Ļ┤ĆļĀ©ļÉśņ¢┤ ņ׳ņ¦Ć ņĢŖļŖöļŗżļŖö ņĀÉņŚÉņä£ ņ¦äļ│┤ļ¦żņ▓┤ņŚÉņä£ ņäØļ®┤ņØä ļŹö ļ¦ÄņØ┤ ļŗżļŻ©Ļ│Ā ņ׳ļŗżĻ│Ā ļ│╝ ņłś ņ׳ļŗż(Appendix 3).
ņØ┤ ņżæņŚÉņä£ ņäØļ®┤Ļ│╝ ņ¦üņĀæ Ļ┤ĆļĀ©ļÉ£ ĒåĀĒöĮ, ņ”ē Ļ▒┤ļ¼╝, Ēśäņן ņäØļ®┤ Ļ▓ĆņČ£, ņäØļ®┤ Ēö╝ĒĢ┤ņ×É, ņāØĒÖ£ņĀ£ĒÆł ņäØļ®┤ Ļ▓ĆņČ£ ĒåĀĒöĮņØä ņóĆ ļŹö ņ¦æņżæņĀüņ£╝ļĪ£ ņé┤ĒÄ┤ļ│┤ņĢśļŗż(Appendix 4). ĒåĀĒöĮ 2(Ļ▒┤ļ¼╝, Ēśäņן ņäØļ®┤ Ļ▓ĆņČ£)ņØś Ļ▓ĮņÜ░ ņ¦äļ│┤ņ¢ĖļĪĀņŚÉņä£ ļŹö ļ¦ÄņØ┤ ļŗżļżäņ¦ĆĻ│Ā ņ׳ņ£╝ļ®░ Ļ▒┤ļ¼╝, ņ▓ĀĻ▒░, ņŖ¼ļĀłņØ┤ĒŖĖ, Ļ│Ąņé¼ ļō▒ņØś ņŻ╝ņĀ£ņ¢┤Ļ░Ć ļīĆļæÉļÉśĻ│Ā ņ׳ņ¦Ćļ¦ī, ļ│┤ņłśņ¢ĖļĪĀņØĆ ļ¦ÄņØ┤ ļŗżļŻ©Ļ│Ā ņ׳ņ¦Ć ņĢŖņ£╝ļ®░ ņŻ╝ļĪ£ ĻĄÉņ£Ī, ļ¦łņØä ļō▒ņØ┤ ĒĢĄņŗ¼ņ¢┤ļĪ£ ļéśĒāĆļé¼ļŗż(Appendix 4A). ņØ┤ņŚÉ ĻĖ░ļ░śņØä ļæś ļĢī ņ¦äļ│┤ņ¢ĖļĪĀņØĆ Ļ│Ąņé¼ĒśäņןņØś ļ¼ĖņĀ£ļź╝, ļ│┤ņłśņ¢ĖļĪĀņØĆ ņ¦ĆņŚŁ ĻĄÉņ£Īņŗ£ņäżņØś ļ¼ĖņĀ£ņŚÉ ņ┤łņĀÉņØä ļ¦×ņČöĻ│Ā ņ׳ļŗż. ļśÉĒĢ£ ĒåĀĒöĮ 3(ņäØļ®┤ Ēö╝ĒĢ┤ņ×É)ņØś Ļ▓ĮņÜ░ ļ│┤ņłśņ¢ĖļĪĀĻ│╝ ņ¦äļ│┤ņ¢ĖļĪĀņØś ņ¢┤Ē£śņŚÉņä£ ļæÉļō£ļ¤¼ņ¦ä ņ░©ņØ┤ļź╝ ļ│┤ņśĆļŗż(Appendix 4B). ļ│┤ņłś ņ¢ĖļĪĀņØĆ ņŻ╝ļ»╝, Ļ┤æņé░ ļō▒ ĒÖśĻ▓Į ļ¼ĖņĀ£ļź╝, ņ¦äļ│┤ņ¢ĖļĪĀņØĆ ņĢö, ĒÅÉņĢö, Ēö╝ĒĢ┤ņ×É ļō▒ ņ¦łļ│æ ļ¼ĖņĀ£ļź╝ ņżæņĀÉņĀüņ£╝ļĪ£ ļŗżļŻ©Ļ│Ā ņ׳ņŚłļŗż. ļŗżņØī ĒåĀĒöĮ 5(ņāØĒÖ£ņĀ£ĒÆł ņäØļ®┤ Ļ▓ĆņČ£)ļź╝ ņé┤ĒÄ┤ļ│┤ļ®┤, ļ│┤ņłśņ¢ĖļĪĀņØĆ ņŻ╝ļĪ£ ĒÖöņןĒÆłņŚÉņä£ ņäØļ®┤ ņä▒ļČäņØ┤ Ļ▓ĆņČ£ļÉ£ Ļ▓āņØä ļ¼ĖņĀ£ ņé╝Ļ│Ā ņ׳ņ¦Ćļ¦ī, ņ¦äļ│┤ņ¢ĖļĪĀņØĆ ņĢĮĒÆłņŚÉņä£ ņäØļ®┤ ņä▒ļČäņØ┤ Ļ▓ĆņČ£ļÉ£ Ļ▓āņØä ļ¼ĖņĀ£ļĪ£ ņĀ£ņŗ£ĒĢśĻ│Ā ņ׳ņŚłļŗż(Appendix 4C).
ņ£äņŚÉņä£ ĒÖĢņØĖĒĢĀ ņłś ņ׳ļŖö Ļ▓āņØĆ ļŗżņØīĻ│╝ Ļ░Öļŗż. ņ▓½ņ¦Ė, ņ¦äļ│┤ņ¢ĖļĪĀņØ┤ ņäØļ®┤ņØä ļŹö ļ╣äņżæ ņ׳Ļ▓ī ļŗżļŻ©Ļ│Ā ņ׳ņŚłļŗż. ļæśņ¦Ė, ļ│┤ņłśņ¢ĖļĪĀņØĆ ņŗżņāØĒÖ£Ļ│╝ Ļ┤ĆļĀ©ļÉ£ ĒåĀĒöĮņØä ņŻ╝ļĪ£ ļé┤ņäĖņøĀņ¦Ćļ¦ī, ņ¦äļ│┤ņ¢ĖļĪĀņØĆ Ļ│Ąņé¼Ēśäņן, ņ¦łļ│æ ļō▒ ņóĆ ļŹö ņé¼ĒÜīņÖĆ Ļ┤ĆļĀ©ļÉ£ ĒåĀĒöĮļōżņØä ņŻ╝ļĪ£ ļŗżļŻ©Ļ│Ā ņ׳ņŚłļŗż. ņģŗņ¦Ė, ļ│┤ņłśņ¢ĖļĪĀĻ│╝ ņ¦äļ│┤ņ¢ĖļĪĀņØ┤ ņäØļ®┤ ļ¼ĖņĀ£ļź╝ ļČĆĻ░üĒĢśļŖö Ļ┤ĆņĀÉņŚÉ ņ░©ņØ┤Ļ░Ć ņ׳ņØīņØä ĒÖĢņØĖĒĢĀ ņłś ņ׳ļŗż.
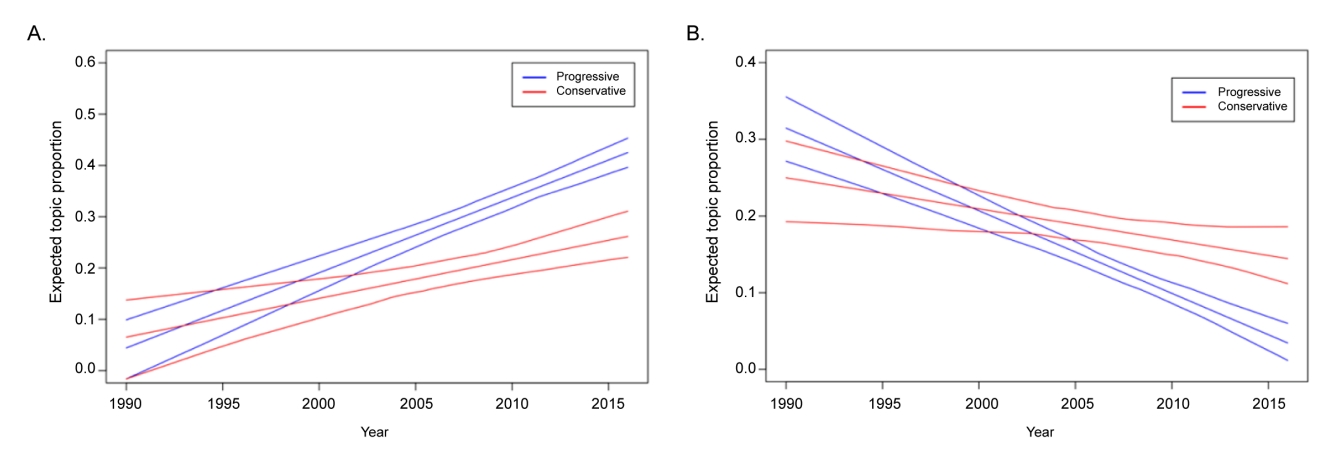
2) ņŗ£ĻĖ░ ļ░Å ņĀĢĒīīņä▒ņØ┤ ĒåĀĒöĮ ļ╣äņ£©ņŚÉ ļ»Ėņ╣śļŖö ņśüĒ¢ź
ņØ┤ņ¢┤ņä£ ņŗ£ĻĖ░ņŚÉ ļö░ļźĖ ĒåĀĒöĮļ╣äņ£©ņØś ļ│ĆĒÖöļź╝ ņé┤ĒÄ┤ļ│┤ņĢśļŗż(Figure 4). ĒåĀĒöĮ 1, 3, 5ļŖö ņŗ£ĻĖ░ņŚÉ ļö░ļØ╝ ņ£ĀņØśļ»ĖĒĢ£ ļ│ĆĒÖöĻ░Ć Ļ┤Ćņ░░ļÉśņ¦Ć ņĢŖņĢśļŗż. ļ░śļ®┤, ĒåĀĒöĮ 2(Ļ▒┤ļ¼╝, Ēśäņן ņäØļ®┤ Ļ▓ĆņČ£)ļŖö 1990ļģäļÅäņŚÉ Ļ▒░ņØś ļéśĒāĆļéśņ¦Ć ņĢŖļŗżĻ░Ć 2015ļģäņŚÉ Ļ░ĆĻ╣īņøīņ¦łņłśļĪØ ĻĘĖ ļ╣łļÅäĻ░Ć ņ”ØĻ░ĆĒĢśņŚ¼ 2015ļģäņŚÉļŖö 30%ļź╝ ļäśņ¢┤ņä£Ļ│Ā ņ׳ņŚłļŗż(Figure 4A). ļ░śļ®┤, ĒåĀĒöĮ 4(ļ░£ņĢöļ¼╝ņ¦ł)ņÖĆ ĒåĀĒöĮ 6(ņé¼Ļ│Ā)ņØś Ļ▓ĮņÜ░ 1990ļģäļÅäņŚÉļŖö ĻĘĖ ļ╣äņ£©ņØ┤ ļåÆļŗżĻ░Ć ņŗ£Ļ░äņØ┤ ņ¦Ćļéśļ®┤ņä£ ĻĘĖ ļ╣äņ£©ņØ┤ ņĀÉņ░© Ļ░ÉņåīĒĢśņŚ¼ 2015ļģäņŚÉļŖö Ļ▒░ņØś ļ╣äņżæņØ┤ ņé¼ļØ╝ņĪīļŗż(Figure 4B). ņ”ē 1990ļģäļīĆ ņäØļ®┤ņØĆ ņŻ╝ļĪ£ ļ░£ņĢöļ¼╝ņ¦łņØś ĒĢśļéśļĪ£ ņé¼Ļ│ĀĒśäņןņŚÉņä£ ļģĖņČ£ļÉśļŖö Ļ▓āņ£╝ļĪ£ ņØĖņŗØļÉśĻ│Ā ņ׳ņŚłņ£╝ļéś ņĄ£ĻĘ╝ ļōżņ¢┤ņä£ļ®┤ņä£ ņĀÉņ░© Ļ▒┤ņČĢļ¼╝Ļ│╝ Ļ│Ąņé¼ĒśäņןņŚÉņä£ņØś ņäØļ®┤ Ļ▓ĆņČ£ņØ┤ ņżæņÜöĒĢ£ ļ¼ĖņĀ£ļĪ£ ļīĆļæÉļÉśĻ│Ā ņ׳ņØīņØä ņĢī ņłś ņ׳ņŚłļŗż. ļ░śļ®┤ ņäØļ®┤ Ēö╝ĒĢ┤ņ×Éļéś ņāØĒÖ£ĒÖśĻ▓ĮņŚÉņä£ņØś ņäØļ®┤ ļ¼ĖņĀ£ņŚÉ ļīĆĒĢ£ ļ¼ĖņĀ£ ņØĖņŗØņØĆ ņŗ£Ļ░äņŚÉ ļö░ļØ╝ Ēü¼Ļ▓ī ļ│ĆĒÖöĻ░Ć ņŚåļŗżļŖö ņĀÉļÅä ĒÖĢņØĖĒĢĀ ņłś ņ׳ņŚłļŗż.
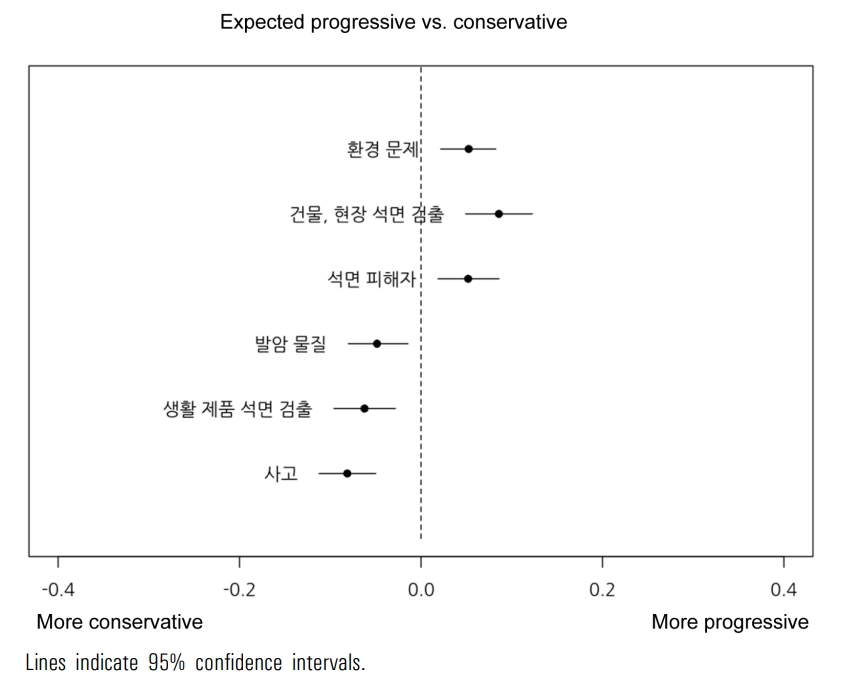
ņĀĢĒīīņä▒Ļ│╝ ņŗ£ĻĖ░Ļ░Ć ļÅÖņŗ£ņŚÉ ĒåĀĒöĮļ╣äņ£©ņŚÉ ļ»Ėņ╣śļŖö ņśüĒ¢źņØä ļČäņäØĒĢ£ Ļ▓░Ļ│╝, ĒåĀĒöĮ 1, 3, 5, 6ņŚÉņä£ļŖö Ļ▓ĮĒ¢źņä▒ņŚÉ Ēü░ ņ░©ņØ┤Ļ░Ć ņŚåņŚłļŗż(Figure 5). ļ░śļ®┤, ĒåĀĒöĮ 2(Ļ▒┤ļ¼╝, Ēśäņן ņäØļ®┤ Ļ▓ĆņČ£)ņØś Ļ▓ĮņÜ░ ņ£äņØś ņŗ£Ļ│äņŚ┤ļČäņäØņŚÉņä£ ļ│Ė Ļ▓āņ▓śļ¤╝ 1990ļģäļīĆņŚÉļŖö ļ¬©ļōĀ ņ¢ĖļĪĀņØ┤ ļ│äļĪ£ ļŗżļŻ©Ļ│Ā ņ׳ņ¦Ć ņĢŖļŗżĻ░Ć ņĀÉņ░© ņ”ØĻ░ĆĒĢśņśĆļŗż(Figure 5A). ņØ┤ļĢī ņ¦äļ│┤ņ¢ĖļĪĀņØ┤ ņØ┤ ĒåĀĒöĮņØä ļŹö ļ¦ÄņØ┤ ļŗżļŻ©Ļ│Ā ņ׳ņŚłļŗż. ļśÉĒĢ£ ĒåĀĒöĮ 4(ļ░£ņĢöļ¼╝ņ¦ł)ņØś Ļ▓ĮņÜ░ 1990ļģäļīĆņŚÉ ņ¦äļ│┤ņ¢ĖļĪĀņØ┤ ļīĆļīĆņĀüņ£╝ļĪ£ ļŗżļŻ©ņŚłņ¦Ćļ¦ī, 2015ļģäņŚÉ Ļ░ĆĻ╣īņøīņ¦Ćļ®┤ņä£ ņ¦äļ│┤ņ¢ĖļĪĀņØĆ ņØ┤ ņŻ╝ņĀ£ļź╝ Ļ▒░ņØś ļŗżļŻ©ņ¦Ć ņĢŖĻ│Ā ņ׳ņŚłļŗż(Figure 5B). ļ░śļ®┤, ļ│┤ņłśņ¢ĖļĪĀņØĆ ņĀüņØĆ ņ¢æņØ┤ļéśļ¦ł ĒĢ┤ļŗ╣ ĒåĀĒöĮņØä Ļ│äņåŹĒĢśņŚ¼ ļŗżļŻ©Ļ│Ā ņ׳ņØīņØ┤ Ļ┤Ćņ░░ļÉśņŚłļŗż. ņ£äņØś ņŗ£Ļ│äņŚ┤ļČäņäØņŚÉņä£ ĒÖĢņØĖĒĢ£ Ļ▓āņ▓śļ¤╝ ņĀäņ▓┤ņŚÉņä£ ņØ┤ ĒåĀĒöĮņØ┤ ņ░©ņ¦ĆĒĢśļŖö ļ╣äņ£©ņØĆ Ļ░ÉņåīĒĢ£ Ļ▓āņ£╝ļĪ£ ļéśĒāĆļéśļŖöļŹ░, ĻĘĖĻ▓āņØĆ ļ│┤ņłśņ¢ĖļĪĀņØś ĻĖ░ņé¼ļ¤ēņØ┤ ĻĖ░ļ│ĖņĀüņ£╝ļĪ£ ņĀüĻĖ░ ļĢīļ¼ĖņØ┤ļŗż.
Ļ│Ā ņ░░
ļ│Ė ļģ╝ļ¼ĖņŚÉņä£ ĒÖ£ņÜ®ĒĢ£ ĒģŹņŖżĒŖĖ ļČäņäØļ░®ļ▓ĢņØĆ Ēæ£ļ│Ėņ×ÉļŻīļź╝ ĒåĄĒĢ£ ņøÉņ×ÉļŻīņØś ņłśņ╣ś ņČöņĀĢņØ┤ļéś ĒÜīĻĘĆļ¬©ĒśĢ ĻĄ¼ņČĢņØä ĒåĄĒĢ£ ļ│ĆņłśņØś ņäżļ¬ģļĀźņØä ĒÖĢņØĖĒĢśļŖö ļ░®ņŗØņØ┤ ņĢäļŗī ļ¬©ņ¦æļŗ© ļśÉļŖö ĻĘĖņŚÉ Ļ░ĆĻ╣īņÜ┤ Ēü░ ĻĘ£ļ¬©ņØś ņ×ÉļŻīļź╝ ņłśņ¦æĒĢśņŚ¼ ņ×ÉļŻīļź╝ Ļ░Ćņן ņל ņäżļ¬ģĒĢĀ ņłś ņ׳ļŖö ļ¬©ĒśĢņØä ņĀ£ņŗ£ĒĢśļŖö Ļ▓āņØä ļ¬®Ēæ£ļĪ£ ĒĢ£ļŗż. ļ¼╝ļĪĀ ņ×ÉļŻīņłśņ¦æņØ┤ ņ¢┤ļĀĄĻ│Ā ņĖĪņĀĢĻĖ░ņżĆ ņäżņĀĢņØś ļ¼ĖņĀ£Ļ░Ć ņ׳ļŖö ņØśĒĢÖņ×ÉļŻī ņĀäļ░śņØä ļīĆņāüņ£╝ļĪ£ ĻĖ░Ļ│äĒĢÖņŖĄļ░®ļ▓ĢņØä ņØ╝ļ░śĒÖöĒĢśļŖö Ļ▓āņØĆ ņ¢┤ļĀżņÜ░ļ®░, ņśżĒ׳ļĀż ĻĖ░ņĪ┤ņØś ĒåĄĻ│äĒĢÖņĀü ļ░®ļ▓ĢņØ┤ ļŹö ĒāĆļŗ╣ĒĢ£ Ļ▓░Ļ│╝ļź╝ ņĀ£ņŗ£ĒĢĀ ņłś ņ׳ļŖö ņśüņŚŁņØ┤ ļ¦ÄļŗżļŖö ņŻ╝ņןņØ┤ ņĀ£ĻĖ░ļÉśĻ│Ā ņ׳ļŗż[35]. ĒĢśņ¦Ćļ¦ī ļ╣ģ ļŹ░ņØ┤Ēä░ļź╝ ĒåĄĒĢ£ ņĀæĻĘ╝ņØ┤ ņØśĒĢÖņŚÉ Ļ░ĆņĀĖņś¼ ņØ┤ņĀÉņŚÉļŖö ņŚ¼ļ¤¼ Ļ░Ćņ¦ĆĻ░Ć ņ׳ņ£╝ļ®░, MurdochĻ│╝ Detsky [36]ļŖö ļ╣ģ ļŹ░ņØ┤Ēä░Ļ░Ć ņāłļĪ£ņÜ┤ ņ¦ĆņŗØņØś ņāØņé░, ņ¦ĆņŗØņØś ļ│┤ĻĖē, ņŗ£ņŖżĒģ£ ņāØļ¼╝ĒĢÖĻ│╝ ļ│æņøÉņ×ÉļŻīņØś ĒåĄĒĢ®ņØä ļ░öĒāĢņ£╝ļĪ£ ĒĢ£ ņĀĢļ░ĆņØśĒĢÖņØś ĒÖ£ņÜ®, ĒÖśņ×É ņĖĪļ®┤ņŚÉņä£ņØś ņĀĢļ│┤ ĒÖĢļīĆĻ░Ć ņØśļŻīņĀäļŗ¼ņØä ĒśüņŗĀĒĢĀ Ļ▓āņØ┤ļØ╝Ļ│Ā ļ│┤ņĢśļŗż.
ļ©╝ņĀĆ ņŚ░ĻĄ¼ņé¼ļĪĆļź╝ ĒåĄĒĢ┤ ļæÉ Ļ░Ćņ¦Ć Ļ░ĆņäżņØä Ļ▓Ćņ”ØĒĢĀ ņłś ņ׳ļŖöņ¦Ćļź╝ Ļ▓ĆĒåĀĒĢ┤ļ│┤ņ×É. ņ▓½ ļ▓łņ¦Ė Ļ░ĆņäżņØĖ ĒÖśņ×ÉņØś ļČłĒÄĖ, Ļ│ĀĒåĄņŚÉ Ļ┤ĆĒĢ£ ņŻ╝ņĀ£Ļ░Ć ļéśĒāĆļéśļŖöĻ░ĆņŚÉ ņ׳ņ¢┤ ĒåĀĒöĮ 3ņØ┤ ņäØļ®┤ Ēö╝ĒĢ┤ņ×Éļź╝ ļŗżļŻ©Ļ│Ā ņ׳ņ£╝ļéś ņäĖļČĆņĀüņ£╝ļĪ£ ļ│╝ ļĢī ņ¦łļ│æĻ│╝ ņåīņåĪ, ĒÖśĻ▓ĮņØä ņżæņŗ¼ņ£╝ļĪ£ ĻĄ¼ņä▒ļÉśņ¢┤ ĒÖśņ×ÉņØś Ļ│ĀĒåĄņØ┤ļéś ļČłĒÄĖņŚÉ Ļ┤ĆĒĢ£ ņŻ╝ņĀ£ļŖö ņל ļō£ļ¤¼ļéśĻ│Ā ņ׳ņ¦Ć ņĢŖņØīņØä ĒÖĢņØĖĒĢĀ ņłś ņ׳ņŚłļŗż(Appendix 4). ļŗżņØī, ņĀĢĒīīņä▒ņŚÉ ļö░ļØ╝ ĒåĀĒöĮņØś ņ░©ņØ┤Ļ░Ć ļéśĒāĆļéśļŖöĻ░ĆņŚÉ Ļ┤ĆĒĢ┤ņä£ļŖö Ļ▓░Ļ│╝ 3ņŚÉņä£ ĒÖĢņØĖĒĢ£ Ļ▓āņ▓śļ¤╝ ļ¬ģĒÖĢĒĢ£ ņ░©ņØ┤ļź╝ Ļ┤Ćņ░░ĒĢĀ ņłś ņ׳ņŚłņ£╝ļ®░, ņØ┤Ļ▓āņØĆ ņĀĢĒīīņä▒ņŚÉ ļö░ļØ╝ Ļ░ÖņØĆ ĒśäņŗżņØ┤ ļŗżļź┤Ļ▓ī ņĀ£ņŗ£ļÉ£ļŗżļŖö ĒöäļĀłņØ┤ļ░Ź ņØ┤ļĪĀņØś ņŻ╝ņןņØä ņŗ£Ļ░üĒÖöĒĢśņŚ¼ ļ│┤ņŚ¼ņŻ╝ļŖö ĒĢśļéśņØś ņé¼ļĪĆĻ░Ć ļÉ£ļŗż. Ļ▓░Ļ│╝ 2ņÖĆ 3ņŚÉņä£ ĒÖĢņØĖĒĢĀ ņłś ņ׳ļŖö Ļ▓āņ▓śļ¤╝ ņĀĢĒīīņä▒ņŚÉ ļö░ļØ╝ ņŗĀļ¼ĖņØĆ ņäØļ®┤ņØ┤ļØ╝ļŖö Ļ░ÖņØĆ ĒśäņŗżņØä ņä£ļĪ£ ļŗżļźĖ ļ¬©ņŖĄņ£╝ļĪ£ ĒśĢņāüĒÖöĒĢśĻ│Ā ņ׳ļŗżļŖö ņĀÉņØ┤ ļéśĒāĆļé£ļŗż.
ļæÉ ļ▓łņ¦Ė Ļ░ĆņäżņØä ĻĄ¼ņ▓┤ņĀüņ£╝ļĪ£ ņé┤ĒÄ┤ļ│┤ņ×Éļ®┤ ņÜ░ņäĀ, ņ¢ĖļĪĀņØś ĻĖ░ņé¼ ņłś ņ░©ņØ┤ņŚÉņä£ ļ│┤ņłśņĀüņØĖ ņ¢ĖļĪĀņØĆ ņäØļ®┤ņØä ļŹ£ ņ¢ĖĻĖēĒĢśļŖö ļ░®Ē¢źņ£╝ļĪ£, ņ¦äļ│┤ņĀüņØĖ ņ¢ĖļĪĀņØĆ ņäØļ®┤ņØä ļ¦ÄņØ┤ ņ¢ĖĻĖēĒĢśļŖö ļ░®Ē¢źņ£╝ļĪ£ ņäØļ®┤ ļ¼ĖņĀ£ņŚÉ ņĀæĻĘ╝ĒĢśĻ│Ā ņ׳ņŚłļŗż. KimĻ│╝ Cheong [22]ņØś ĻĄŁņĀĢņøÉ ļ»╝Ļ░ä ņé¼ņ░░ ņØśĒś╣Ļ│╝ ļ»╝Ļ░äņØĖ ņé¼ņ░░ ņŻ╝ņןņŚÉ ļīĆĒĢ£ ņ¢ĖļĪĀļ│┤ļÅä ņŚ░ĻĄ¼ņŚÉ ļö░ļź┤ļ®┤, ļ¦żņ▓┤ļŖö ņĀĢĒīīņä▒ņŚÉ ļö░ļØ╝ ņØśļÅäņĀüņ£╝ļĪ£ ņé¼Ļ▒┤ņØä ļ░░ņĀ£ĒĢ£ļŗż. ļŗżņŗ£ ļ¦ÉĒĢśļ®┤ ņĀĢĒīīņä▒ņŚÉ ļö░ļØ╝ ņŗĀļ¼Ėļ¦żņ▓┤Ļ░Ć ĒŖ╣ņĀĢ ņŻ╝ņĀ£ļź╝ ļŗżļŻ©ļŖö ļ╣łļÅäĻ░Ć ļŗ¼ļØ╝ņ¦äļŗżļŖö Ļ▓āņØ┤ļ®░ Ļ░ÖņØĆ Ļ▓░Ļ│╝Ļ░Ć ņäØļ®┤ ĻĖ░ņé¼ņŚÉņä£ļÅä Ļ┤Ćņ░░ļÉ©ņØä ĒÖĢņØĖĒĢĀ ņłś ņ׳ņŚłļŗż.
ļŗżņØī, Lakoff [19,20,37]ļŖö ņØĖņ¦ĆņØ┤ļĪĀĻ│╝ ņŗĀĻ▓ĮĻ│╝ĒĢÖņŚÉ ĻĖ░ļ░śņØä ļæÉņ¢┤ ņé¼Ļ▒┤ņØä ņĀ£ņŗ£ĒĢśļŖö ĒŗĆ, ņ”ē ŌĆśĒöäļĀłņØ┤ļ░ŹŌĆÖņŚÉ ļö░ļØ╝ ņé¼ļ×īļōżņØ┤ ļŗżļź┤Ļ▓ī ļ░śņØæĒĢśļ®░, ĻĘĖĻ▓āņØĆ ļÅäļŹĢņĀü ĻĖ░ļ░śņŚÉ ĒśĖņåīĒĢ£ļŗżĻ│Ā ņŻ╝ņןĒĢśņśĆļŗż. ĒĢ£ĻĄŁņŚÉņä£ļŖö ļ│┤ĒÄĖ ļ│Ąņ¦ĆņÖĆ ņäĀļ│äļ│Ąņ¦ĆņŚÉ ĒśĖņåīĒĢśļŖö ŌĆśļ¼┤ņāüĻĖēņŗØŌĆÖĻ│╝ ŌĆśņäĀļ│äĻĖēņŗØŌĆÖņØś ĒöäļĀłņØ┤ļ░ŹņØ┤ ļģ╝ļ×ĆņØ┤ ļÉ£ ņĀüņØ┤ ņ׳ļŗż. Lem [38]ņØĆ ļ│┤ņłś, ņ¦äļ│┤ņŗĀļ¼ĖņØś ļ¼┤ņāüĻĖēņŗØ ļģ╝ņ¤ü ĒöäļĀłņØ┤ļ░ŹņØä ļČäņäØĒĢśņśĆņ£╝ļ®░, ļŗ┤ļĪĀņ£ĀĒśĢņŚÉ ĻĖ░ņ┤łĒĢśņŚ¼ ļ│┤ņłśņÖĆ ņ¦äļ│┤ ņ¢ĖļĪĀņØś ļīĆĒĢŁ ļŗ┤ļĪĀ 6Ļ░Ćņ¦Ćļź╝ ĒīīņĢģĒĢśņśĆļŗż. ņŚ¼ĻĖ░ņä£ ļŗ┤ļĪĀņØ┤ļ×Ć ļ»┐ņØīĻ│╝ Ļ▓¼ĒĢ┤ņØś ņ¢Ėņ¢┤ņĀü ņ×¼ĒśäņØ╝ ļ┐Éļ¦ī ņĢäļŗłļØ╝ ĻČīļĀźņØś ļ░śņśüņØ┤ņ×É ĻĘĖ ĻĄ¼ĒśäņØ┤ļŗż[39]. ĻĘĖļ¤¼ļéś Lem [38]ņØś ņŚ░ĻĄ¼ļŖö ļŗ┤ļĪĀņ£ĀĒśĢņØä ļ»Ėļ”¼ ņäĀņĀĢĒĢśĻ│Ā ņäĀņĀĢļÉ£ ļŗ┤ļĪĀņØä ļīĆĒæ£ĒĢĀ ņłś ņ׳ļŖö ĻĖ░ņé¼ņĀ£ļ¬®ņØ┤ļéś Ēæ£Ēśä, ņØĆņ£Āļź╝ ņ░ŠņĢäļ│┤ļŖö ļ░®ņŗØņ£╝ļĪ£ ņĀæĻĘ╝ĒĢśņśĆņ£╝ļ®░ ņØ┤Ļ▓āņØ┤ ņĀüņĀłĒĢ£ ļČäņäØļ░®ļ▓ĢņØ┤ļØ╝Ļ│Ā ļ│┤ĻĖ░ņŚÉļŖö ņØśļ¼ĖņØś ņŚ¼ņ¦ĆĻ░Ć ņ׳ļŗż. ļŗ┤ļĪĀņ£ĀĒśĢņØś ņäĀņĀĢ ņØ┤ņ£Ā, ĻĘĖļ”¼Ļ│Ā ņäĀņĀĢļÉ£ ļŗ┤ļĪĀņØ┤ Ļ│╝ņŚ░ ņŗĀļ¼ĖĻĖ░ņé¼ņŚÉ ņ¢╝ļ¦łļ¦īĒü╝ņØ┤ļéś ļō£ļ¤¼ļéĀ Ļ▓āņØĖņ¦ĆņŚÉ Ļ┤ĆĒĢ£ ļČäņäØņØ┤ ņĀ£ņŗ£ļÉśņ¦Ć ņĢŖņĢśĻĖ░ ļĢīļ¼ĖņØ┤ļŗż.
ļ│Ė ļģ╝ļ¼ĖņØś ņé¼ļĪĆļŖö ņ¦äļ│┤ņ¢ĖļĪĀņØ┤ ņé¼ĒÜīņĀü ļŗ┤ļĪĀņØä, ļ│┤ņłśņ¢ĖļĪĀņØ┤ ņŗżņāØĒÖ£Ļ│╝ Ļ┤ĆļĀ©ĒĢ£ ļŗ┤ļĪĀņØä ņĀ£ņŗ£ĒĢśĻ│Ā ņ׳ņØīņØä Ļ┤Ćņ░░ĒĢśņśĆņ£╝ļ®░, ņ×ÉļŻīļź╝ Ļ▓ĆĒåĀĒĢśĻĖ░ ņĀä ļ»Ėļ”¼ ņäĀņĀĢĒĢ£ ļŗ┤ļĪĀņ£ĀĒśĢņØ┤ļéś ĒöäļĀłņØ┤ļ░ŹņŚÉ ļ¦×ņČ░ ĻĖ░ņé¼ļź╝ ņ×¼ļŗ©ĒĢśļŖö Ļ▓āņØ┤ ņĢäļŗłļØ╝ ņ×ÉļŻī ļé┤ņŚÉņä£ ļŗ┤ļĪĀņØä ņ░ŠņĢäļé┤ļ®░, ĻĘĖĻ▓āņØ┤ ņ¦äļ│┤ņÖĆ ļ│┤ņłśņØś Ļ▓¼ĒĢ┤ ņ░©ņØ┤ņŚÉ ļö░ļØ╝ ņ¢┤ļ¢ż ņŗØņ£╝ļĪ£ ņ░©ņØ┤ļź╝ ļéśĒāĆļé┤ļŖöņ¦Ć ņŗ£Ļ░üĒÖöĒĢśņŚ¼ ņĀ£ņŗ£ĒĢśņśĆļŗżļŖö ļŹ░ņŚÉņä£ ĻĘĖ Ļ░Ćņ╣śĻ░Ć ņ׳ļŗż. ļśÉĒĢ£ ĻĖ░ņĪ┤ ņŚ░ĻĄ¼ņŚÉņä£ ņĀ£ņŗ£ĒĢ£ Ļ▓¼ĒĢ┤Ļ░Ć ņäØļ®┤ ĻĖ░ņé¼ņŚÉņä£ļÅä Ļ░ÖņØ┤ ļéśĒāĆļéśļŖö Ļ▓āļÅä ĒÖĢņØĖĒĢĀ ņłś ņ׳ņŚłļŗż. FeinbergņÖĆ Willer [40]ļŖö ĒÖśĻ▓ĮņŚÉ Ļ┤ĆĒĢ£ Ēā£ļÅäĻ░Ć ņĀĢĒīīņä▒ņŚÉ ļö░ļØ╝ ņ░©ņØ┤ļź╝ ļ│┤ņØ┤ļ®░ ņ¦äļ│┤ļŖö ļ│┤ņłśļ│┤ļŗż Ēö╝ĒĢ┤ņÖĆ ļÅīļ┤ä(harm and care)ņØś ļÅäļŹĢņĀü ņČĢņŚÉ ņśüĒ¢źņØä ļŹö ļ¦ÄņØ┤ ļ░øļŖöļŗżĻ│Ā ļ│┤Ļ│ĀĒĢśņśĆļŗż. ļ│Ė ņé¼ļĪĆņŚÉņä£ļÅä ņ¦äļ│┤ņ¢ĖļĪĀņŚÉņä£ ĒśäņןĻ│╝ ņ¦łļ│æņØś ļŗ┤ļĪĀņØ┤ ļŹö ļæÉļō£ļ¤¼ņ¦ĆĻ▓ī ļéśĒāĆļéśĻ│Ā ņ׳ņØīņØä ĒÖĢņØĖĒĢśņśĆļŗż. ļ░śļ®┤ ļ│┤ņłśņ¢ĖļĪĀņØĆ Ļ░£ņØĖņĀü ņĖĪļ®┤ņŚÉ ļŹö Ļ░ĆĻ╣īņÜ┤ ĻĄÉņ£Ī, ĒÖśĻ▓Į, ĒÖöņןĒÆł ļō▒ņØä ļŗ┤ļĪĀņØś ņČĢņ£╝ļĪ£ ņé╝ņĢä ņäØļ®┤ņØä ņĀ£ņŗ£ĒĢśĻ│Ā ņ׳ņŚłļŗż.
ņØ┤ ņŚ░ĻĄ¼ļ░®ļ▓ĢļĪĀņ£╝ļĪ£ Ļ▓Ćņāē Ļ░ĆļŖźĒĢ£ ļ¬©ļōĀ ņŗĀļ¼ĖĻĖ░ņé¼ļź╝ ļ¬©ņĢä ļČäņäØĒĢĀ ņłś ņ׳ļŗżļŖö Ļ▓āņØĆ Ļ▓░Ļ│╝ņØś ĒāĆļŗ╣ņä▒ņØä ļ│┤Ļ░ĢĒĢśĻĖ░ļŖö ĒĢśļéś ņŗĀļó░ļÅäļź╝ Ļ▓Ćņ”ØĒĢĀ ĒĢäņÜöĻ░Ć ņ׳ļŗż. ņ”ē ņé¼ļĪĆņØś ņŚ░ĻĄ¼Ļ▓░Ļ│╝ņØś ļ│┤Ļ░ĢņØä ņ£äĒĢ┤ņä£ļŖö ļæÉ ļČäļźśļĪ£ ņłśņ¦æĒĢ£ ĻĖ░ņé¼ļź╝ ļÅģņ×ÉņŚÉĻ▓ī ņĀ£ņŗ£ĒĢśļŖö ļ░®ņŗØņŚÉ ļö░ļØ╝ņä£ ĻĘĖļōżņØ┤ ņäØļ®┤ņŚÉ Ļ┤ĆĒĢ┤ Ļ░Ćņ¦ĆļŖö ņØśĻ▓¼ņØ┤ ņ¢┤ļ¢╗Ļ▓ī ļ│ĆĒÖöĒĢśļŖöņ¦Ć ĒÖĢņØĖĒĢĀ ĒĢäņÜöĻ░Ć ņ׳ļŗż. ĒöäļĀłņØ┤ļ░ŹņØ┤ ĒÖśĻ▓ĮņŚÉ Ļ┤ĆĒĢ£ ņØśĻ▓¼ņØ┤ ļ»Ėņ╣śļŖö ņśüĒ¢źņØä Ļ▓ĆĒåĀĒĢ£ ĻĖ░ņĪ┤ ņŗ¼ļ”¼ĒĢÖņĀü ņŚ░ĻĄ¼ņŚÉņä£ ĒÖ£ņÜ®ĒĢ£ ĒÅēĻ░Ćļ░®ļ▓ĢņØä ļÅäņ×ģĒĢśņŚ¼ ņČöĻ░ĆņĀüņØĖ ņŚ░ĻĄ¼ļź╝ ņ¦äĒ¢ēĒĢśļŖö Ļ▓āņØ┤ ĒĢäņÜöĒĢĀ Ļ▓āņ£╝ļĪ£ ļ│┤ņØĖļŗż[40,41].
ņØ┤ļĀćĻ▓ī ĒģŹņŖżĒŖĖ ļČäņäØ, ĒŖ╣Ē׳ ĒåĀĒöĮ ļ¬©ļŹĖļ¦üņØĆ Ļ┤Ćņŗ¼ ņŻ╝ņĀ£ņØś ĒģŹņŖżĒŖĖļź╝ ļīĆļ¤ēņ£╝ļĪ£ ņłśņ¦æĒĢ£ Ļ▓ĮņÜ░ ņØ┤ļź╝ ĒÜ©Ļ│╝ņĀüņØ┤Ļ│Ā ļ╣Āļź┤Ļ▓ī ļČäņäØĒĢśļŖö ļ░®ļ▓ĢņØä ņĀ£ņŗ£ĒĢśņŚ¼ ĻĖ░ņĪ┤ ņŚ░ĻĄ¼ļ░®ļ▓ĢņŚÉņä£ ļČäņäØĒĢśĻĖ░ ņ¢┤ļĀĄļŗżĻ│Ā ļŖÉĻ╗┤ņĪīļŹś ļ¼ĖņĀ£ļź╝ ĒāÉĻĄ¼ĒĢ┤ļ│╝ ņłś ņ׳ļŖö ĻĖĖņØä ņĀ£ņŗ£ĒĢ£ļŗż. ņØ┤Ļ▓āņØĆ ĒŖ╣Ē׳ ņØśļŻīņÖĆ Ļ┤ĆļĀ©ļÉ£ ņé¼ĒÜīņĀü ļ¼ĖņĀ£ļéś ņłśņ╣śļĪ£ļŖö Ēæ£ĒśäĒĢśĻĖ░ ņ¢┤ļĀżņøĀļŹś ņØśļŻīņĀü ĒśäņŗżņØä ņŚ░ĻĄ¼ĒĢśĻ│Ā ņØ┤ļź╝ ņŗ£Ļ░üĒÖöĒĢśņŚ¼ ņĀ£ņŗ£ĒĢĀ ņłś ņ׳ļŖö ļ░®ļ▓ĢļĪĀņØä ņĀ£ņŗ£ĒĢ£ļŗżļŖö ņĀÉņŚÉņä£ Ļ░ĢņĀÉņØä ņ¦Ćļŗīļŗż. ļśÉĒĢ£ ĒģŹņŖżĒŖĖ Ļ┤ĆļĀ© ņŚ░ĻĄ¼ļź╝ ņłśĒ¢ēĒĢśļ®┤ņä£ ĻĖ░ņĪ┤ņØś ņ¦łņĀü ņŚ░ĻĄ¼Ļ░Ć ņ¦ĆļŗłļŖö ļé£ņĀÉ, ņ”ē ņØśļŻī Ļ┤ĆļĀ© ņŚ░ĻĄ¼ļź╝ ņ¦äĒ¢ēĒĢśĻĖ░ ņ£äĒĢ£ ņ×¼ņøÉņØś ĒĢ£Ļ│ä, ĻĖ░ĒÜŹ ļ░Å ņłśĒ¢ēņŚÉ ĒĢäņÜöĒĢ£ ĻĖ░ņłĀ, ņŗ£Ļ░ä, ļģĖļĀźņØś ņ¢æ, ļŖźņłÖĒĢ£ ņŚ░ĻĄ¼ņ×ÉņØś ļČĆņĪ▒Ļ│╝ Ļ░ÖņØĆ ļ¼ĖņĀ£ ņĀ£ĻĖ░ņŚÉ ļīĆĒĢ£ ļīĆņĢłņØä ņĀ£ņŗ£ĒĢĀ ņłś ņ׳ņØä Ļ▓āņ£╝ļĪ£ ļ│┤ņØĖļŗż[42,43].
ņ▓śņØī ņ¦łļ¼Ėņ£╝ļĪ£ ļÅīņĢäĻ░Ćņä£ ņØ┤ ļ░®ļ▓ĢņØä ņØśĒĢÖĻĄÉņ£ĪĒśäņןņØś ĻĖ░Ļ│äĒĢÖņŖĄĻĄÉņ£ĪņŚÉ ĒÖ£ņÜ®ĒĢĀ ņłś ņ׳ļŖöņ¦Ćļź╝ ņé┤ĒÄ┤ļ│┤ņ×É. ņä£ļæÉņŚÉņä£ ņĀ£ņŗ£ĒĢ£ Ļ▓āĻ│╝ Ļ░ÖņØ┤ ņØśĒĢÖĻĄÉņ£ĪņŚÉņä£ ĻĖ░Ļ│äĒĢÖņŖĄņØä Ļ░Ćļź┤ņ│ÉņĢ╝ ĒĢĀ ĒĢäņÜöņä▒ņØĆ ņŗ£ĻĖēĒĢśļéś, ĒĢÖņŖĄņŚÉ ĒĢäņÜöĒĢ£ ņ×ÉļŻīņÖĆ ĻĖ░Ļ│äĒĢÖņŖĄļ¬©ĒśĢņØä ņ░ŠĻĖ░ ņ¢┤ļĀżņÜ░ļ®░, ĒĢÖņāØļōżņØ┤ ĒØźļ»Ėļź╝ ļŖÉļü╝Ļ│Ā ņ×ÉņŗĀņØś ņŚ░ĻĄ¼ļź╝ ņłśĒ¢ēĒĢĀ ņłś ņ׳ļŖö ņŚ░ĻĄ¼ļ░®ļ▓ĢņØä ņĀ£ņŗ£ĒĢśĻĖ░ ņ¢┤ļĀĄļŗżļŖö ļé£ņĀÉņØ┤ ņĪ┤ņ×¼ĒĢ£ļŗż. ļ│Ė ļģ╝ļ¼ĖņŚÉņä£ ņĀ£ņŗ£ĒĢ£ ņŚ░ĻĄ¼ņé¼ļĪĆļź╝ ņØśĻ│╝ļīĆĒĢÖņŚÉņä£ņØś ļŹ░ņØ┤Ēä░ Ļ│╝ĒĢÖĻĄÉņ£ĪņŚÉ ņØæņÜ®ĒĢśņŚ¼ ņāüĻĖ░ņØś ļ¼ĖņĀ£ļź╝ ĒĢ┤Ļ▓░ĒĢĀ ņłś ņ׳ņØä Ļ▓āņ£╝ļĪ£ ļ│┤ņØĖļŗż. ĒģŹņŖżĒŖĖ ļČäņäØņØĆ ĒĢÖņāØļōżņŚÉĻ▓ī ĻĖ░Ļ│äĒĢÖņŖĄņØ┤ ņĀäĒåĄņĀüņØĖ ĒåĄĻ│äĒĢÖĻ│╝ļŖö ļŗżļźĖ ļ╣äņĀĢĒśĢ ņ×ÉļŻīļéś ļīĆĻĘ£ļ¬© ņ×ÉļŻīļź╝ ļŗżļŻ░ ņłś ņ׳ņØīņØä ļ│┤ņŚ¼ņżĆļŗż. ļśÉĒĢ£ ļ│Ė ļģ╝ļ¼ĖņØś ņé¼ļĪĆņŚÉņä£ ņĀ£ņŗ£ĒĢ£ ļ░®ļ▓ĢļĪĀņØĆ ĒĢÖņāØļōżņØ┤ ņé¼ĒÜī ņØśĒĢÖņĀü Ļ░ĆņäżņØä ņäżņĀĢĒĢśĻ│Ā, ļŹ░ņØ┤Ēä░ ļČäņäØņØä ĒåĄĒĢ┤ ņŚ░ĻĄ¼ļź╝ ņŗ£ļÅäĒĢĀ Ļ░ĆļŖźņä▒ņØä ņĀ£ņŗ£ĒĢ£ļŗż. ļŹöļČłņ¢┤ ĒĢÖņāØļōżņØ┤ ņ×ÉņŗĀņØś ļ¼ĖņĀ£ļź╝ ņäżņĀĢĒĢśĻ│Ā, ņ¦üņĀæ ņ×ÉļŻīļź╝ ĻĄ¼ņČĢĒĢśļ®░, ņ¦üņĀæ ļ¬©ĒśĢņØä ļ¦īļōżņ¢┤ļ│╝ ņłś ņ׳ņ£╝ļ»ĆļĪ£ ĒĢÖņāØļōżņØś ņ░ĖņŚ¼ļÅäņÖĆ ņØ┤ĒĢ┤ļÅäĻ░Ć ļåÆņĢäņ¦ł Ļ▓āņ£╝ļĪ£ ĻĖ░ļīĆĒĢ┤ļ│╝ ņłś ņ׳ļŗż. ļśÉĒĢ£ ļŗ©ņł£ĒĢ£ ĒåĄĻ│ä Ēī©Ēéżņ¦Ć ĒÖ£ņÜ®ļ▓Ģ ĻĄÉņ£Īļ┐Éļ¦ī ņĢäļŗłļØ╝ ņ¢┤ļŖÉ ņĀĢļÅäņØś ĒöäļĪ£ĻĘĖļלļ░Ź ĻĖ░ļ▓ĢņŚÉ Ļ┤ĆĒĢ£ ņØ┤ĒĢ┤Ļ░Ć ĒĢäņÜöĒĢśļ»ĆļĪ£ ĒĢÖņāØļōżņŚÉĻ▓ī ņĄ£ĻĘ╝ ņÜöĻĄ¼ļÉśĻ│Ā ņ׳ļŖö ņĮöļö® ļ░Å ņĢīĻ│Āļ”¼ņ”ś(coding and algorithm) ĻĄÉņ£ĪņØä ņ£äĒĢ£ ņĀæĻĘ╝ļ▓Ģņ£╝ļĪ£ ĒÖ£ņÜ®ĒĢĀ ņłś ņ׳ļŗżļŖö ņןņĀÉņØä ņ¦Ćļŗīļŗż.
ņØ┤ ļģ╝ņØśĻ░Ć Ļ░Ćņ¦ĆļŖö ĒĢ©ņØśļŖö ņØśĒĢÖĻĄÉņ£ĪņŚÉņä£ ĒĢÖņāØļōżņØ┤ ņØśļŻīņĀü ļ¼ĖņĀ£ļź╝ ļ░öļØ╝ļ│┤ļŖö ļ░®ņŗØņŚÉ Ļ┤ĆĒĢ£ ņŗ¼ļÅä ņ׳ļŖö ļģ╝ņØśļź╝ ņ┤ēņ¦äĒĢĀ ņłś ņ׳ļŗżļŖö Ļ▓āņØ┤ļŗż. ņĢ×ņä£ ņ¢ĖĻĖēĒĢ£ Ļ▓āņ▓śļ¤╝ ļ│Ė ņŚ░ĻĄ¼ņØś ņé¼ļĪĆņŚÉņä£ ĒÖ£ņÜ®ĒĢ£ ĒåĀĒöĮ ļ¬©ļŹĖļ¦üņØĆ ĻĘĖļÅÖņĢł ļŹ░ņØ┤Ēä░ Ļ│╝ĒĢÖņŚÉņä£ ļŗżļŻ©ĻĖ░ ņ¢┤ļĀżņøĀļŹś ļ╣äĻĄ¼ņĪ░ĒÖöļÉ£ ņ×ÉļŻīņØś ĒĢśļéśņØĖ ĒģŹņŖżĒŖĖļź╝ ņ▓śļ”¼ĒĢśļŖö ļ░®ļ▓ĢņØä ņĀ£ņŗ£ĒĢ£ļŗż. ņØ┤ ļ░®ļ▓ĢļĪĀņØĆ ņØśĒĢÖĻĄÉņ£ĪņØś ņŗżņĀ£ņŚÉņä£ ņĀüņÜ® Ļ░ĆļŖźņä▒ņØä ņ¦Ćļŗīļŗż. ņØśĒĢÖĻĄÉņ£ĪĒśäņןņŚÉņä£ ņĄ£ĻĘ╝ ĻĖĆņō░ĻĖ░ņÖĆ ņä▒ņ░░ ĻĖ░ļĪØņØ┤ Ļ░ĢņĪ░ļÉśļ®┤ņä£ ĒĢÖņāØļōżņØś ņä£ņłĀņ×ÉļŻīļź╝ ļČäņäØĒĢĀ ļ░®ļ▓ĢņØ┤ ņÜöņ▓ŁļÉśĻ│Ā ņ׳ļŗż. ņ¦äļŻīĒśäņןņŚÉņäĀ ņØśļŻīņ¦äņØ┤ ĻĖ░ļĪØĒĢ£ ņĀäņ×ÉņØśļ¼┤ĻĖ░ļĪØ(electronic medical record) ļō▒ņØś ņĀäņ×Éļ¼Ėņä£ļź╝ ļČäļźś, ļČäņäØ, ņ▓śļ”¼ĒĢśļŖö ļ░®ļ▓ĢņŚÉ Ļ┤ĆĒĢ£ ņŚ░ĻĄ¼Ļ░Ć ĒĢäņÜöĒĢśļŗż. ļśÉĒĢ£ ĒÖśņ×ÉņÖĆ ņØśļŻīņ¦ä Ļ░üĻ░üņØ┤ ņØĖĒä░ļäĘ Ļ│ĄĻ░äņŚÉ ļé©ĻĖ┤ ņ¦äļŻīĒśäņןĻ│╝ ņ¦łļ│æņØś ĒśäņןņŚÉņä£ ņØ╝ņ¢┤ļé£ ņØ╝, Ļ▓¬ņØĆ ņØ╝ņŚÉ Ļ┤ĆĒĢ£ ĻĖ░ļĪØņØä ļČäņäØĒĢśņŚ¼ ņØśļŻīĻ▓ĮĒŚśņØä ĒÖĢņØĖĒĢĀ ņłś ņ׳ļŗż. ņŗĀļ¼ĖĻ│╝ ļ░®ņåĪļ¦żņ▓┤ļŖö ņØśĒĢÖņØä ļæśļ¤¼ņŗ╝ ņŚ¼ļ¤¼ ņé¼Ļ▒┤ņØä ņĀäļŗ¼ĒĢśļ®░, ņŚ¼ĻĖ░ņŚÉņä£ ņāØņä▒ļÉśļŖö ņłśļ¦ÄņØĆ ļ¼Ėņä£ļŖö ņØśĒĢÖĻ│╝ ņØśļŻīļź╝ ņØ┤ĒĢ┤ĒĢśļ®░, ĒÖśņ×ÉņÖĆ ņØśņé¼ļź╝ ļæśļ¤¼ņŗ╝ ņ¦łĒÖśĻ│╝ ņé¼ĒÜīļź╝ ĒĢ┤ņäØĒĢśļŖö ļŹ░ņŚÉ ņ׳ņ¢┤ņä£ ĒĢäņłśņĀüņØĖ ņ×ÉļŻīĻ░Ć ļÉ£ļŗż.
ĻĘĖļ¤¼ļéś ņ¦ĆĻĖłĻ╣īņ¦ĆļŖö ņØ┤ļ¤░ ĒģŹņŖżĒŖĖ ņ×ÉļŻīļź╝ ļČäņäØĒĢśĻĖ░ ņ£äĒĢ£ ņĀüņĀłĒĢ£ ļÅäĻĄ¼Ļ░Ć ņŚåņŚłĻĖ░ ļĢīļ¼ĖņŚÉ ņØ┤ļź╝ ļŗżļŻ©ļŖö ļŹ░ņŚÉ ņ¢┤ļĀżņøĆņØ┤ ņ׳ņŚłļŗż. ņ¦łņĀü ņŚ░ĻĄ¼ļź╝ ĒåĄĒĢ┤ņä£ ļČäņäØĒĢĀ ņłś ņ׳ņ¦Ćļ¦ī, ņłÖļĀ©ļÉ£ ņŚ░ĻĄ¼ņ×Éļ¦īņØ┤ ņłśĒ¢ēĒĢĀ ņłś ņ׳ļŗżļŖö ņĀæĻĘ╝ņä▒ņØś ņØ┤ņŖłļŖö ņØśĒĢÖĻ│╝ ņ¦łņĀü ņŚ░ĻĄ¼ ļ¬©ļæÉņŚÉ Ļ┤ĆĒĢ£ ņŗ¼ļÅä ņ׳ļŖö ņ¦ĆņŗØņØä Ļ░¢ņČś ņŚ░ĻĄ¼ņ×ÉĻ░Ć ļō£ļ¼╝ļŗżļŖö ļ¼ĖņĀ£ļź╝ ņĀ£ĻĖ░ĒĢśĻ│Ā ņ׳ļŗż. ļśÉĒĢ£ Ēśä ņØśĒĢÖĻĄÉņ£ĪĒÖśĻ▓ĮņŚÉņä£ ņ¦łņĀü ņŚ░ĻĄ¼ņÖĆ Ļ░ÖņØ┤ ņłśĒ¢ēņŚÉ ļ¦ÄņØĆ ņŗ£Ļ░äņØ┤ ļō£ļŖö ņŚ░ĻĄ¼ ļ░®ļ▓ĢņØä ĒĢÖņāØļōżņŚÉĻ▓ī Ļ░Ćļź┤ņ╣śļŖö Ļ▓āņØĆ ĒśäņŗżņĀüņ£╝ļĪ£ ĒĢ£Ļ│äĻ░Ć ņ׳ļŗżļŖö ļ¼ĖņĀ£ļÅä ņĪ┤ņ×¼ĒĢ£ļŗż[44]. ļ│Ė ņŚ░ĻĄ¼ņé¼ļĪĆņŚÉņä£ ĒÖ£ņÜ®ĒĢ£ ņŚ░ĻĄ¼ļ░®ļ▓ĢļĪĀņØĆ ņŗ£Ļ░äĻ│╝ ņ▓śļ”¼ļ░®ļ▓ĢņØś ļ¼ĖņĀ£ļĪ£ ĻĘĖļÅÖņĢł ņĀæĻĘ╝ĒĢśĻĖ░ ņ¢┤ļĀżņøĀļŹś ļ¼Ėņä£ļź╝ ļ╣Āļź┤Ļ│Ā Ļ░äļץĒĢśĻ▓ī ņĀĢļ”¼ĒĢśļ®░, ĻĘĖ Ļ▓░Ļ│╝ļź╝ ļŗżļźĖ ņłśņ╣śņÖĆ Ļ▓░ĒĢ®ĒĢśņŚ¼ ļČäņäØņØś ņ×ÉļŻīļĪ£ņŹ© ņĀ£ņŗ£ĒĢ£ļŗż. ņØ┤ ļ░®ļ▓ĢļĪĀņØä ĒåĄĒĢ┤ ĒģŹņŖżĒŖĖ ņ×ÉļŻīļź╝ ļŹö ĒÅŁļäōĻ▓ī ņØ┤ĒĢ┤ĒĢśņŚ¼ ņØśļŻīņĀü ļ¼ĖņĀ£ņØś ņé¼ĒÜīņĀü, ļ¼ĖĒÖöņĀü ņ░©ņøÉņØä Ļ▓ĆĒåĀĒĢĀ ņłś ņ׳ļŖö ĒåĀļīĆļź╝ ņĀ£ņŗ£ĒĢĀ ņłś ņ׳ļŗż.
ļŹ░ņØ┤Ēä░ Ļ│╝ĒĢÖņØś ļ¼╝Ļ▓░ņØ┤ ņé¼ĒÜī Ļ░ü ņśüņŚŁĻ│╝ ņĀäļ¼Ėņ¦üņØś ļ│ĆĒÖöļź╝ ņÜöĻĄ¼ĒĢśļŖö ĒśäņŗżņŚÉņä£ ņØśĒĢÖĻĄÉņ£ĪņØĆ ļŹ░ņØ┤Ēä░ ļČäņäØļ░®ļ▓ĢļĪĀņØä Ļ░Ćļź┤ņ│ÉņĢ╝ ĒĢśĻ│Ā, ņØśļŻī ņĀäļ¼Ėņ¦üņØĆ ņØśļŻīĒśäņןņŚÉņä£ ĒÖ£ņÜ®ĒĢĀ ņłś ņ׳ļŖö ļŹ░ņØ┤Ēä░ ļČäņäØĻĖ░ļ▓ĢņŚÉ Ļ┤ĆĒĢ£ ņŚ░ĻĄ¼ļź╝ ņłśĒ¢ēĒĢ┤ņĢ╝ ĒĢ£ļŗż[45]. ņØśļŻīņØĖņØ┤ ļ╣ģ ļŹ░ņØ┤Ēä░ņÖĆ ļ│┤Ļ▒┤ņĀĢļ│┤ĒĢÖ(health informatics)ņŚÉ Ļ┤ĆĒĢ£ ņ¦ĆņŗØņØä Ļ░¢ņČöļŖö Ļ▓āņØĆ ļŗ©ņ¦Ć ņØśļŻīņØĖņØś ņāØņĪ┤ļ┐Éļ¦ī ņĢäļŗłļØ╝ ĒÖśņ×ÉņÖĆ ļ│┤ĒśĖņ×É, ļŹö ļéśņĢäĻ░Ć ņé¼ĒÜī ļ¬©ļæÉļź╝ ņ£äĒĢ£ ņØ╝ņØ┤ ļÉĀ Ļ▓āņØ┤ļŗż[46]. ĻĖ░Ļ│äĒĢÖņŖĄņØä ĒåĄĒĢ£ ņśłĒøä ņśłņĖĪņØś Ē¢źņāü, ņØ╝ļČĆ ņØśļŻīņ×æņŚģņØś ļīĆņ▓┤, ņ¦äļŗ© ņĀĢĒÖĢņä▒ņØś Ļ░£ņäĀņØ┤ ņØśļŻīļź╝ Ēü¼Ļ▓ī ļ│ĆĒÖöņŗ£Ēé¼ Ļ▓āņØ┤ļØ╝ļŖö ņśłņĖĪņØ┤ ņĀ£ņŗ£ļÉśĻ│Ā ņ׳ļŗż. ļ¼╝ļĪĀ ņ¦äļŗ©ņØś ļ¬©ĒśĖĒĢ©, ņØśļŻīņ×ÉļŻī ņ▓śļ”¼ņØś ĒĢ£Ļ│ä, ĻĖ░Ļ│äĒĢÖņŖĄņØä ĒåĄĒĢ┤ ĻĄ¼ņČĢĒĢ£ ļ¬©ĒśĢņØś Ļ▓Ćņ”Ø ĒĢäņÜöņä▒ņØĆ ņØ┤ ļ│ĆĒÖöņØś ņåŹļÅäļź╝ ļŖ”ņČ£ Ļ▓āņØ┤ļŗż. ņØśļŻīņŚÉ ņ¦üņĀæņĀüņØĖ ņśüĒ¢źņØä ļ»Ėņ╣Ā ļĢīĻ╣īņ¦Ć ņĢäņ¦ü ņŗ£Ļ░äņØ┤ ļé©ņĢäņ׳ļŖö ņ¦ĆĻĖł, ļ»ĖļלņØś ņŻ╝ņŚŁņØ┤ ļÉĀ ņØśĻ│╝ļīĆĒĢÖ ĒĢÖņāØļōżņŚÉĻ▓ī ĻĖ░Ļ│äĒĢÖņŖĄ Ļ┤ĆļĀ© ĻĄÉņ£ĪņØä ņ£äĒĢ£ ņĀüņĀłĒĢ£ ļ░®ļ▓ĢļĪĀņØä ļģ╝ņØśĒĢ┤ņĢ╝ ĒĢ£ļŗż.




 PDF Links
PDF Links PubReader
PubReader ePub Link
ePub Link Full text via DOI
Full text via DOI Download Citation
Download Citation Print
Print